P1:

大家晚上好,首先谢谢群主的邀请和组织这次网上课程。这样的分享,我觉得这是一个非常有意义的事情。我今天和大家分享的是SerDes的一个简单介绍。
P2:

第二张PPT是关于我们今天讲的一个主要内容。第一部分,我们先介绍一下背景,讲述为什么要做SerDes,SerDes是干什么的。第二部分是讲SerDes的第一个内容timing,与时钟相关的,然后介绍SerDes的第二个内容,关于数据或者是信号、信号处理。
然后给大家分享一下,近年来比较流行的或者是主要的SerDes设计结构。最后把前面的两部分整合在一起和大家介绍。
P3:

十几年前也就是2000年的时候,基本上很多接口还都是并行的。我们这里举了一个例子在2002年有个PCI x3.0,它是一种并口。同时这一年intel发明了这个PCIe 1.0,这是一个串口。PCIX这是64bit的一个并口,每个通道是1.066Gbps。
在最初的计算机接口技术中主要是使用PCI接口。而这个intel发明的PCIE结构呢,它是一个创新的。它用了SerDes技术。它的一个通道是2.5G,然后它可以是x1,x2,x4,x8和x16。
从总体来看呢,英特尔这个x16 的PCIE 1.0还没有它那个64bit乘以1.066g的PCIX 3.0速度高,但是它没有向前馈clock。因为x16总共有32根线,它的线会少一些。并且这个并口需要有一个同步的clock,它会从TX这边传一个同步clock到RX那边作为前馈同步时钟。这个同步clock的频率是数据的速度的一半,也就是采用DDR这种双边沿采样结构。
但是它这个pciex3.0发布出来之后没有商用。因为它是64bit并行的,在接收端数据之间会相互错开。比如说64bit之间错开之后,它们之间没办法用一个clock可把它们同时接收过来。
最关键的是PCIE是一个串口,所以它存活了下来,一直到现在。PCIe4 16G,PCIe5 32g。最近有很多产品就要出来了。PCIE4去年的时候有很多公司的产品研发出来用在soc上。PCIE5的IP基本上很多公司应该是ready了。
比如X16这种16路,它们之间是相互没有关系的。那每一路采样只需要照顾到自己这一路,把数据收进来就可以了。这是它的一个优越性,它不需要像并口那样有64路的同步。64路并口速度高,但是它有一点通路的不匹配就会导致最终的Phase error,然后在RX这边就会出现接收问题。
还有就是串口的速度越来越快,它可以节省大量的IO。为芯片拥有更高的吞吐率提供了一个可能性。比如PCIE-4单通道的数据率已经达到了16Gbps。
这边是目前用的比较多的一些SerDes环境。下面这个图是一个CPU和GPU通过一个背板连在一起,下面这个是通过一根同轴线cable连在一起。
目前,比如说USB3.1,或者我们视频中用的HDMI,基本上这个速度都会比较高,然后还有更高的就是在光纤通信中CEI-28G、CEI-56G的标准已经出来了,并且在Ethernet里边IE802.03ba/bg/bs,bg是28Gbps、bs是56Gbps,标准也出来了。
P4:

这张PPT里面的图就是在一个Ethernet的应用。在数据中心中,很多像这个冰箱一样的柜子,里面是很多交换机芯片。交换机芯片在这个板卡上通过这个母板连在一起。这里边的很多SerDes都是10Gbps/40Gbps的这种速度。这个40Gbps其实是四个10Gbps一起的速率,也就是4-lane的10Gbps的SerDes。这种是基于802.3 ba协议的,这种现在基本上在很多数据中心已经使用了。
P5:

那么在数据中心使用的这种芯片到芯片的这种互联或者switch交换机,它有一个环境就是背板或者PCB背版,还有一些connector等都有很多loss或者是reflection等等,并且这些loss和它的频率是相关的。另外,SerDes之间的channel都不是很理想,还有很多cross talk。这些loss,reflection和crosstalk和这个板材做的长度、通孔个数等等非常相关。而这些环境会使得设计SerDes非常困难,因为它会导致信号衰减,并且会加入很多非理想的噪声、干扰等等。
P6:

P7:

这边呢,就是一个刚才我们提到的那个channel的特性。这里第一张图给出了三种它的传输函数,或者说它的s21。在不同的长度,loss区别很大。我们看到第一个蓝色的,它的loss就会比较小,在2.5Gbps时loss大概不到5db;而红色的这种比较长,它的loss在2.5Gbps的时候就有10个dB多一些。这个绿色的一根线,它不光loss多一点,还在10Gbps时有一个很差的一个点的loss,到-60多dB。
一般在设计的时候,会拿一个channel的model一般是Sparameter或者是LGC这种model,然后在前仿真/后仿真去验证我们的design。
从它的冲击响应可以看到红色的在4ns前面一点开始上升,比如说在4ns前一点去sample它,那么可以得到一个数据。但是在后面,比如说4ns多一点的时候去sample它,也可能得到1个1,本来应该是得到了1个0,这就会产生一个错误的数据。
单位冲激响应叠加之后,就会产生一个眼图。或者在PRBS的输入下,折叠输出之后会得到一个眼图。我们看到这个眼图在不同的channel上它的opening,就是高度、宽度差别非常大的。
P8:

比如在第一个图上面看到这个数据就很容易在Rx这边接收到。第二张图相对来说一个比较好的比较器,也是能分辨出来的。那第三张图中eye就完全就闭合了。在这种情况下怎么去收到数据,并且我们怎么去发送数据,这都是一个比较有挑战的事情。另外5Gbps数据的奈奎斯特频率是2.5GHz,也就是说它的能量主要集中在2.5GHz以内。
P9:

并且我们看到,同样是红色的这一根channel它对于5Gbps数据的响应和10Gbps的响应完全不一样。对于5Gbps可以看到还有一点eyeopening,但是当速率上升到10Gbps的时候eye就完全闭合了。那就问题来了,我们再怎么从10Gbps这个眼图中恢复出数据呢,那如果要是速度再进一步上升,比如说到28Gbps,那我们又怎么去恢复出数据呢,这是SerDes需要解决的问题。使得它有一个最好的setup time、hold time等等。
P10:

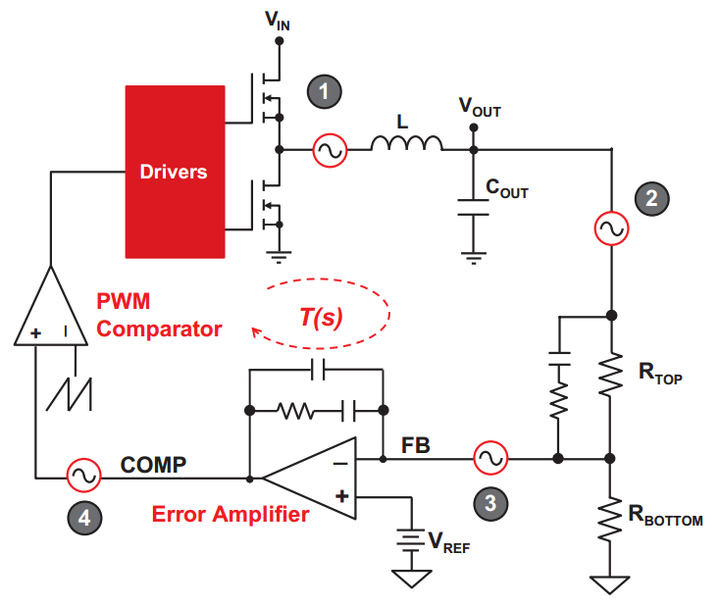
这是一个SerDes的基本结构图。前面就是把并行数据转换成串行数据(一般也叫MUX),然后再给TX发送出去。因为channel本征阻抗是50Ω,所以TX这边加一个termination,50Ω的特征阻抗来保证阻抗匹配。Rx这边同样加一个50Ω特征阻抗来保证匹配,这样才没有反射。然后RX和TX这边分别有负责时序的,比如说PLL和Timing Recovery,这些模块专门为这些电路提供clock。
在这里我主要把它分成两部分,第一部分就是timing,为发送和接收数据提供clock;第二部分就是signaling,就是信号处理。TX边主要是把数据发送出去保证一定的眼高,然后Rx这边把数据恢复出来。因为channel loss之后,signal可能是看不到的。这就说RX主要做两件事,既要恢复数据、又要恢复时序。恢复数据就是要知道是0还是,对于这种PAM 2也就是NRZ类数据来说。并且要找到怎么去、在哪个时间点上去sample这个data,也就是恢复出一个最好的timing。看到下面有个时序图,Rx clock的上升沿采在这个数据它的正中间,center sample,这样一般是最好的。
P11:

这里提到BER,如果收到的数据有错误,那么错误的数据和总共收到数据的比值就是误码率BER。Timing上的error和signal上的error都会引起error,都会恶化BER。
误码率BER和noise有一个对应关系。一般要求BER是低于10的-12次方,对应14个sigma的 noise,这里说的noise是Random noise,而sigma就是我们平时说的RMS值。
那么timing上有jitter——Random jitter或者deterministic jitter是都会引起时序上的错误。然后noise同样有随机噪声和确定性噪声。一般BER求在10的-12次方以下,或者更好,有些甚至要求到10的-13次方或者-15次方,这样就会看到更多的噪声。
这个就相当于我们平时,看3个sigma的mismatch,其实这个概率大概是99.7%。那超过3个sigma的概率是3‰。也就是说,如果我们要保证10的负12次方这样的一个概率的话,我们要看到14个sigma。
P12:

下面就是我们来看一下timing。主要是TX这边transmitter的jitter和PLL,然后RX这边是clockRecovery,我们一般也称之为CDR。
P13:

数据的jitter主要是由clock的jitter决定的,然后加一个C2Q到这边来。
首先,一个随机的数据可能会包含大量的ISI。比如说从电源来的或者是从channel来的。一般,我们会把那个data和clock分开。因为clock不是随机的,它是一个固定的。那么data会干扰clock。然后data上的这些ISI被clock可以滤掉。我们从PPT的第一个图上可以看到,如果data上有jitter,clock的去sample它时候,只要保证setup time满足和hold time满足,那么Q上的jitter和data是没关系的。
第二张图就是说用一个NAND gate,clock 去过滤掉DI上的jitter。和D触发器类似,数据上面有jitter,不会出现在DO这边。
这就说明了我们data上面的jitter其实不是那么在乎,只要保证setuptime、hold time。而clock上的jitter就至关重要。
P14(TX MUX):

这是一个全速率的MUX,它的clock频率和data rate是相同的。这里有一个好的地方就是它最后使用的是一个DFF,而不是用NAND gate。但是它有一个“1UI Critical Path”,如果要保证setup time、hold time,D02这个 DFF的C2Q加MUX的C2Q的delay再加上最后一个DFF的setup time要小于1个UI。这时候让clock工作在和data rate一样的频率,clock的频率较高,routing较困难。
P15(TX MUX):

而Half rate里clock的duty-cycle distortion会影响输出的jitter,因为它不是上升沿触发,而是用clock的高电平去gate掉Dout,或者说是时钟的高低电平选择数据。这时候clock就不需要那么高的频率。但是如果要是再降一下clock的频率,它可以支持在相同的时钟频率下有更高的数据率,但是它更可能会消耗更多的功耗,因为design太复杂了。
P16(Timing):

下面来看一下这个PLL,它主要是为TX,可能也要给RX提供时钟。
P17:

这是一个PLL,这里是一个100M的referenceclock。VCO的时钟经过feedback divider除以一个80后和Reference lock,这样就产生了一个8GHz的clock。PLL里面还有Charge Pump、PFD、LPF等。
P18:

这里简单比较了一下Ring VCO和LC VCO两种区别,不过很多paper或者是资料上都比较这两个区别,我就不再细说了。另外补充一点Ring VCO目前来说有两级、三级、四级、五级,单端和差分的各种结构,三级的这种FOM是最好的,并且是三级单端的这种FOM是最好的。而两级、四级、五级相对都会差一些,五级其实是次之于三级。但有的时候我们需要那个四个Phase,可能就需要四级的,这样的话不得以用四级的,就会降低PLL的FOM。
而LC VCO这边可能也有很多种,包括ClassAB、Class B、Class C、Class D、Class F。基本上2013年就有paper在讲Class D、Class F。Class D在新的工艺下就是当地device的开关电阻非常小时非常优越,因为它在小信号时候晶体管表现为gm,在大信号时候就应该表现出一个开关,所以Class D在新的工艺下是有优越性的。
那么PLL要做到什么样的程度呢,我们来大致算一下。BER为10的-12次方,也就是对应的jitter是14个sigma,也就是说我们可能要看到14个sigma的Jitter。
那么RINGVCO,一般来说可能在5GHz的clock能做到1.5ps的RMS Jitter。有可能会做的更好,但问题是功耗在继续增加。10G的data rate,5GHz的clock就是half rate,14个sigma乘以一个根号2。因为有Rx、TX两端,所以有两个PLL或者是两个VCO,那么它的jitter是1.414×21ps。对于100ps的UI来说占了大概30%,这个地方就是又加上了1点margin。因为14个sigma对应的是10的-12次方,但是我们一般不会真正做到14个sigma,可能会更多。并且对于目前来说比较热门的PAM4来说,它的eye opening会更小,因为它的上升沿有不同transition。这样PAM4的eye opening会小30%。这里的30%具体指的是EYE的宽度,另外EYE的高度比较明显的会小1/3,可能还会更多。
对于14G的clock、28G datarate来说,用RING产生时钟比较困难,并且对这种data rate,jitter要求会更高。比如说RMS jitter 0.2ps,这时候大概占UI的11%。在高频的时候,数据恢复这边(signaling)也会更困难,所以我们尽量要保证这边的Jitter margin多留一点,对于signaling那边来说是一个好处。
P19:

一般来说,不考虑Rx第一个sampler或者说clockedcomparator的Setup time的话,EYE center基本上在正中间,但是有时候还有Setup time的影响,它一般可能不是在正中间。
P20:

P21:

另外一部分就是在RX这边的timingrecovery。这个CDR的主要目的就是找到一个最好的simple点,使得simple的数据尽量多的是对的,也就是说BER尽量的小。那么它找到这个eye可能是正中间,也可能是它最优的一个setup time/hold time点。
和VCO类似,CDR目前也有主要有两种,一种是VCOBASED CDR,还有一种是PI BASED CDR。VCO是个很消耗power的东西,或者DCO。那PI的power就比较小。
VCO的可以用一个线性的phasedetector,或者是Bang-Bang的。线性的有个好处就是它的带宽可以做得很高,不会有很大的非线性引起的噪声,可以用模拟滤波器。如果是Bang-Bang的类型,基本上都是digital滤波器。
PI是相位插值器,通过内插得到新的相位时钟。PI本身不产生clock,需要一个reference clock,也就是说它需要一个PLL给它供clock。它只作为phase的调制,就是搬运phase,左一点右一点,能够克服一小部分的frequency offset,但是很少。
PI有比较大的INL,一般用多相位输入给PI供其选择来减小INL,也就是把相位分段之后再内插。那就是说如果是用LC tank的两个Phase的PLL的话,可能还需要DLL给它产生多个Phase,比如说八个或者是四个。PI一般输出128或者256个phase点是比较好的选择。
P22:

这是一个基于PI的CDR,它是用了BANG-BANGphase detector,非线性但是功耗很低。然后有两条通路去做low pass filter。它这两条通路一个gain主要是调phase,一个gain调frequency。所以它有一定调制frequency的能力,但是很弱。PI实现digital to phase的convertor。一般resolution有128、256等,甚至有些人做得更高。但是更高的话就意味着你的data会很多,片子面积又很大,功耗就会增加。
CDR的主要性能就是jittertolerance,它可以track PLL那边的一部分jitter。还有就是CDR的bandwidth和它的功耗,bandwidth越高功耗就要更高。
P23:

上面基本上把timing的相关信息简单介绍下,下面介绍数据处理方面的内容。
P24:

P25:

这张图就看到我们的tx和Rx的equalization在什么位置。
数据处理主要是均衡器,TX这边叫emphasis,或者叫FFE。RX这边的均衡器会比较多一些,比如说CTLE。有有源的、无源的,可能还会有些其它的滤波器。然后最重要的还有DEF,它有各种结构。在signal里面还会讲一下T-Coll和ESD,因为这两个在高频的时候会显得非常重要。
P26:

有时候那个equalization也就是均衡器可能会不需要,因为如果channel的loss特别好,TX那边直接把信号给发送出来,通过一个50Ω的阻抗匹配。然后RX这边有个50Ω的阻抗匹配,最后直接一个比较器就把它收过来了,这样也是可以的。但是,当channel的insertion loss比较差的时候,这个问题就十分重要了,它可以使得频率响应曲线变得平坦,减少ISI。像刚才说的TX输出阻抗和RX端口阻抗要保证50Ω来匹配channel的阻抗,保证没有反射。在下面的三张图(P26)就是表示均衡器的作用。比如说,Channel一开始时随着频率升高loss越来越大的,但是我如果在5G的时候给它一个gain,而在低频时候没有gain。这样就把5G这个地方给补进来了,看到第三张图绿色的这个就显得比较平坦,这样的ISI就会小。
首先介绍TX端的Equalization。这是一个TX的equalization。这里用了4-tapFFE。除了一个主的以外,前面有一个,后面还有个POST1、POST2,然后都加在一起后经过50Ω输出。这个图的下面也表示了这四个tap是怎么产生的,里面有DFF或者latch产生一个UI一个UI的delay。
P27:

P28:

通过这个PPT来看一下FFE的一个作用,它是怎么消除ISI的。如果没有FFE就是没有pre-emphasis。那么data出来之后高频的信号就变得小。而如果有第一个post的emphasis,可以看到第二张图红色的输出的响应,高频的信号明显变大了,低频信号稍微小一点。
P29:

TX端除了均衡之外还有它的impedance。目前主流的还是有两种,分为电流模和电压模。电压模就是左边这张图。它主要是swing大一些,也就是输出的信号幅度大一点,power可能稍微会低点。但是50Ω阻抗的不是太好,因为它包含了晶体管,意味着晶体管阻抗会随corner变化比较大,然后温飘比较严重,但这个问题可以通过某些方法解决掉。而像右边的图只有一个电阻就很好底下的晶体管是在饱和区的,所以看进去的阻抗非常高,对于对于输出阻抗没有什么影响。
下面我们看一下Rx这边的均衡技术。第一个就是CTLE,连续时间线性均衡器。它主要来补偿channel的loss。它还可以做成是一种无源的,只有RC或者有L。无源的就意味着没有Gain。它只能把低频的减弱,把高平的相对来说是增高能量。并且无源design有个好处就是它不会产生noise,除了R会产生的noise,但是一般来说R会比较小。而晶体管的noise相对多一些。然后CML基本上就是一个放大器,不过它有RC的source degeneration,也就是说在低频时的gain被减弱,而在高平时会有gain。这样产生一个补偿channel的效果。
一般来说CTLE工作的时候功耗会大一些,来保证noise足够小,因为它一般是RX的第一级。另外,在那个奈奎斯特频率,CTLE一般都会有一些Gain。这样后边的noise就不那么敏感了,比如后面VGA、DFE、sampler。第三CTLE一般都是采用可编程的CS、RS,因为channel都不一样,甚至有时还会有自适应算法来自动配置RS、CS。
P30:

P31:

DFE技术(decisionfeedback equalization)。首先来说它会decision,它决定输入的数据是1还是0。第二个它是有feedback。也就是说它把这个收到的数据,通过一条链路返回到输入,然后再输入上直接减掉一些信息。那么减掉的量的多少,也就是它输入的数据会乘以一个系数。它减掉多少电压,就是这个信号的加权(w)是多少。另外,DEF是非线性的,并且channel也是非线性的,很多时候非线性还非常大。这里包含3点,一个就是decision,第二个就是feedback,然后第三个就是它非线性。
第一个点就是DFE的sampler或者slicer,它是个比较器,主要完成判决是0还是1的任务,它把输入信号一个很小的电压放大成CMOS level,或者是接近CMOS level这一个比较大的信号。
P32:

这张PPT来看一下channel的非线性,DFE的非线性可以恰好补偿channel的一些非线性,因为CTLE或者前端的等一些其他的analog基本上都是线性的,而由于channel各种通孔好复杂,使得它有很多非线性。我们看到第二张图,channel的一个单位冲激响应,后面的post cursors可能会非常非常乱,每个tap到底取多少值,是可能会比较任意的。各个tap需要取多少值对于不同的channel也是不一样的,所以基本上都会有一个自适应的电路在里边。
P33:

P34:

这个就是介绍了两个channel,这两个channel不一样,那么它的DFE可能就是要适应这两个channel。并且一般的自适应电路是alwayson,用它来去cover一些电路或者是那些channel的温飘效应得到。自适应的话就需要额外的比较器,并且一直工作。
这个是DFE自适应的一种方法。为了自适应电路中额外加入了一些比较器,并且给这些比较器输入一个voltage offset信号,这些比较器就会产生error信号。然后根据error和data去判断各个tap是偏大还是偏小,在尽量大的voltage offset时,新加入的比较器能比较出相同数量的正确和错误结果,那就表明data的比较器margin比较大,或者是BER比较小。
P35:

P36:

这个是DFE一个致命的特点,就是它的第一个tap的timing必须满足在feedback到来的时候clock的上升沿还没有到,也就是clock到的时候feedback一定ready了。所以,这个timing要求delay和setup time小于一个UI,才能保证这个feedback加进来对下一个信号是有效的。如果这样一个时间保证不了,DFE就不能实现。这里还有一种减小这个限制的方法,那就是非折叠的DFE,它的第一个tap其实是预加在了前面两个比较器上,然后根据前一个数据到底是多少来选择从哪一个比较器拿数据作为输出。
下面是ESD和电感相关的东西。刚才我们讲到了那个DFE的一个致命的特点,下边我们在一些例子中还会继续提到。然后ESD电路的作用大家也都知道,但是它对于高速电路来说有一个不太好的地方,就是它有一个很大的寄生cap,这cap会限制我们的带宽,并且它会减小高频的阻抗,使得impedance imbalance。
P37:

这个就是T-Coil在TX和RX的使用,它基本上就是补偿电路中比较大的CAP。在TX和RX中的连接基本一样的,就是两个电感跨接在大电容的两边,两个电感有互感,其实就是一个线圈T-coil。
P38:

这张PPT是T-coil的版图和它对电路性能的改善情况。
P39:

P40:

Signaling本上就讲完了,然后下面主要看三个例子。由于时间关系,可能下面三个例子,我们会大致的讲一下重点。然后系统的细节上没时间讲太多。
P41:

这是一个28nm 28G的PAM-2的SerDes,它要支持40dBchannel loss。这是2015年的ISSCC,博通的一篇文章。RX直接就是2-Zero CTLE,加了一个4级VGA,然后就是14个Tap的 DFE和DEMUX。后面的就是digital,它包含一些自适应和一些CDR电路,也就是控制PI的 code需要这些digital产生等等。图中的时钟是有一个25G PLL提供的,PLL给它一个6.25G clock,然后自己再用DLL成8个phase再给PI。
它的PI用了6个,也就是产生6个6.25G的clock,它这里是4相位采样,另外两个PI是用给CDR。
PLL是一个LC tank25G的PLL,其实他是支持28GHz的。然后除以2之后再给TX和除以4给RX。TX这边就是MUX,最终应该是SST,也就是我们刚才讲的电压模的一个driver。它有5个tap的FFE,并且loading一个电感来补偿ESD的cap。
P42:

这是他的一个SST driver,讲了5个tap的优点。这是跟我们刚才提到的比较类似。
P43:

这个是他DFE结构,他这里讲了tap1如果是直接反馈的话,timingmeet不了。所以必须用第二种方法,非折叠的tap1,这样的话,他的时序约束就简单了很多。1.5个ts就是3个UI,就是从左边的1个UI变成了3个UI。这个时间约束只是加了一点点,加了一点点tmux的delay。这里有一个不好的地方,就是它比较复杂。对于tap3到tap14的timing就会好做一点。但这个并不是重点,因为tap1都做掉了。
这是他的整体的一个quarter rate的DFE。这边讲quarterrate的一个优点是时钟频率低。然后每一个sampler有selector有更长的时间去恢复数据。也就是regeneration timing会比较长。这样的话,有效的gain会比较大。由于它积分的时间长,比较器看到的噪声就更倾向于低频,高频的噪声会被平均掉。所以,他噪声会减小SNR会好。另外,他有更好的gain所以更sensitive,等于小信号来说也能折射出到底是0还是1。但是low power方面,其实由于clock多了一倍,sampler也是多了一倍。频率降下来了,但是面积增加一倍,功耗并不一定省。
P44:

P45:

这是他的一个测试结果。他用一个一米的背板,有40dB的loss去测的。看到这个eye还是非常好的。中间有很多空白的地方。这就是他的margin。在这种环境下还有这么大的margin。这个是对一个比较差的channel的一个测试,我们可以看到DFE都打开的时候效果还是很好的。
P46:

下面我们来探讨一下PAM-4。PAM-4主要就是把一个signal分成4个幅度,然后一次传2-bit数据。他的奈奎斯特频率相对datarate来说是四分之一,会更小。它可以看到更好的channel loss。如果在相同的channel loss下,他的data rate也会翻倍。但是他更是sensitive to noise,就是眼睛天然就会小了很多,高度小到1/3,也就是9.5个dB,但是由于眼睛的厚度存在这里,他可能比这个9.5dB还更差。由于高度上是4个level,它对于线性度很敏感。从图中很容易看到,PAM4的眼宽更窄,对jitter也是更加敏感。
P47:

这是一个PAM-4的SerDes。是2017年ISSCC Xilinx的文章,还是用DFE做均衡。
P48:

我们看到前面CTLE,AGC之后就是10个tap的DFE。他没有做那么多tap。然后有很多digital的部分用off-chip来control了。
P49:

基本上我们DFE收到的数据,其实是4个level的温度计码,还要编码成2个二进制码。比较器输出3个数据,分别是DH、DZ、DL;对应3个眼。然后还有4个error,4个电压level。所以他有很多比较器,也就是slicer。
P50:

这是DFE的框图,我们看到除了加法器和前面的GM之外。它的比较器很多,center data要3*2个,然后有4个half rate的error level,所以用了7*2个。当然还要自适应,也就是adaptation,这又要额外的sampler,还要有edge。所以加在一起,这个sampler会非常多,并且还是直接反馈的,没有用那种非折叠的。要不然的话,可能要五六十个sampler,非常可怕。
P51:

这张图就是为什么他直接反馈能够做到。首先因为它是14nm。14nm工艺在35.7ps的反馈时间还是可以做到的。如果是频率更高,data rate更高,非折叠的话,我们看到他这里讲了,sampler个数要乘以4。因为他是1个bit比特有4种可能性,这里可能用4倍的sampler。
P52:

这是他的一个half rate sampler,第一个tap直接反馈。他在sampler的第一个latch后面加了一个inverter直接反馈给下边一个数据,他并没有后边再加一个RS触发器,RS latch的delay会比较长。这是直接反馈可行的第二个原因,他为了做到这一点,这里有所创新。
P53:

P54:

23dB channelloss的测试结果。他是做不到太好,但是10的-9次方后面如果加FEC。这是1种数据校验的方法。加了这个之后,他的数据BER也可以恢复到10的-12次方,有FEC后,其实BER基本上在10的-6次方都可以恢复到10的-12次方,这个东西很强大。
P55:

另外呢,也是一个paper,还有18年的一个教程,还是ISSCC的。它里面都提到了ADC的这种方法。ADC的做法可以支持更高的channelloss。但是如果速度在56G的话,上面提到,用DFE也做出来了,可能性能不是太理想,所以也不一定必须用这种PAM-4 ADC的方法。
P56:

这个ADC基本上就是替代了刚才的DFE,但是不只是ADC还有DSP,因为ADC把数据采样到之后不做量化、不做补偿、不做均衡。DSP把这些均衡技术和量化全部做进去了。所以DSP+ADC的功耗肯定要比DFE的功耗高,同样是16nm、相同channel loss的情况下。
但是对于56G这个level是这样,那么112G可能DEF的方法是做不出来的。除此之外,他的提到了TX 4个tap FIR,还有PLL的jitter。
P57:

P58:

这是测试结果,可以支持的channelloss比上面DFE的要多。
P59:

好了,今天我们就是从这4个方面大致介绍一下。SerDes的东西其实是比较复杂的,它涉及到的内容可以非常多。大家有什么问题呢,大家可以讨论,时间也要超过九点了,谢谢大家。


Q1:
哈哈大*:CDR带宽您是怎么选取的呢?
李闻界:一般比PLL带宽大2到4陪,或者更高。主要为了抑制PLL的噪声。
哈哈大*:这个是业内经验吗?
李闻界:我的个人经验。
Q2:
名*:李老师,现在频率这么高,业界CDR环路核心部分用模拟方法多还是数字方法更多?
李闻界:这是他的ADC里边的RX的一个结构,它有PLL和RX。这个RX基本上前部还是一样的,就是到后边有个ADC。7 bit或者3bit Time-InterleavedSar ADC,用32路来替换掉了前面那种方法的DFE。后面又是DSP做上了DFE+FFE和ADC的一些calibration。DSP里面他只做了1个tap的DFE和4个tap的FFE,因为DFE对DSP来说也很难做。
Q3:
高*:问一下50欧姆是片内还是片外?
李闻界:片内。
Q4:
哈哈大*:您觉得对于SerDes的发展趋势而言,今后最大的挑战在哪里?
李闻界:功耗和cost,包括DFE怎么更快,ADC和DSP怎么能更省功耗,怎么可以做的更小。
Q5:
Hi,简单*:你好老师,高速SerDes的功耗是个大问题,在设计的时候是如何考虑?
李闻界:一般来讲,多加rc隔开一些噪声源,不要浪费不必要的功耗,功耗和噪声在系统上分配合理,再就是采用对噪声不敏感的电路结构。
Hi,简单*:非常感谢老师回答,你觉得有没有可能就用CTLE,不用DFE或者ADC用28nm实现28Gbps传输,我觉得DFE和ADC这两东西太吃功耗了
李闻界:@Hi,简单*,看channel,15db loss没问题。很多光通信的都不用DFE。
Q6:
*:请问slicer offset对CDR performance会有影响吗?
李闻界:会。
Q7:
大*:请教T-coil的layout真是那么画吗?互感看起来不大啊。
李闻界:八边形,四边形都可以,互感可以到0.3到0.4吧。
大*:我看到了你PPT里的那个T-coil了,谢谢!
Q8:
大*:bump是什么意思?我真不理解。
李闻界:电感一头是bump,中间是PAD ESD。bump就是要和bounding wire相连的顶层金属。
Q9:
大*:请教一个问题,DFE要等CDR phase lock后打开,到稳定需要多少us的时间?
李闻界:可以同时打开。DFE稳定时间还是CDR稳定时间?
大*:我想请教DFE 稳定时间。
李闻界:几个us,算法不同区别交大,快点的1us。
Q10:
高*:请教一下,经常有打开补偿与不打开的眼图比较,这种是仿真结果还是实测结果?
李闻界:都有,RX里的很多是仿真图。
Q11:
Pice*:CTLE的EQ和VGA先后顺序怎么考虑?
Hanz*:VGA在EQ前面。
Pice*:@Hanz*,VGA在前不是可以降低后级失调和噪声需求吗?但是看到有人喜欢VGA放后面。
李闻界:@Pice*,考虑信号摆幅和噪声,CTLE可以先把低频压下来。
Pice*:@李闻界,对啊,和信号幅度有关。
Hanz*:AGC从哪级detect幅度?
李闻界:@Hanz*一般不detect吧。DSP会做。
Pice*:@李闻界,您的经验,也是VGA在后比较好?
李闻界:@Pice*,是的。特别对于ADC的RX。
Hanz*:不detect 那怎么去控制VGA呢?开环手动调?
李闻界:@Pice*,这个好像大家的做法不太一样。
Hanz*:恩,要看构架了。
Hi,简单*:个人觉得,VGA放前面很容有isi跑出来,低频幅值衰减比较比较小,很容易被放大限幅,而高频部分的放大取决你VGA的-3dB bandwidth,高速的工艺不好,这个很难搞。
Hanz*:看构架吧,PAM4的应该要放在前面。首先要保证前面的线性度。