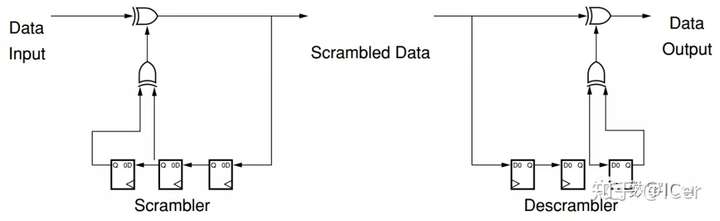
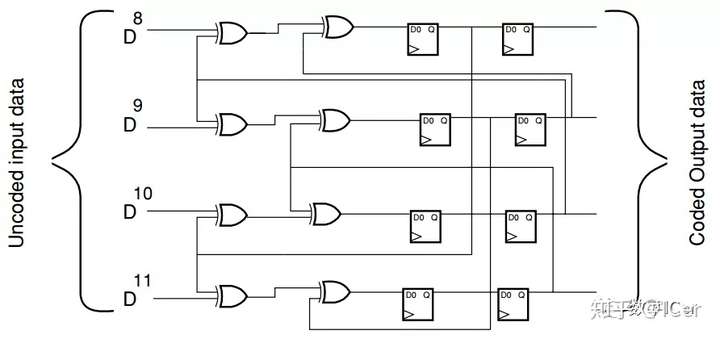
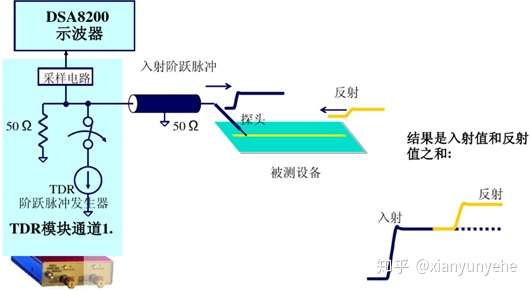
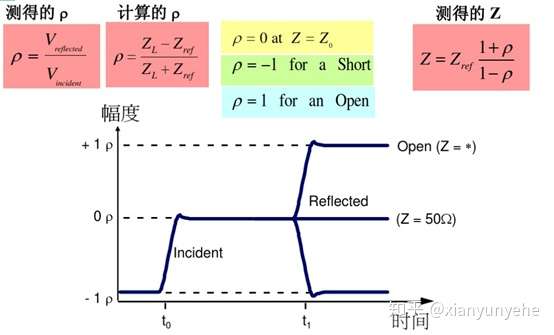
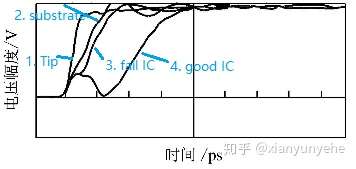
光模块分析(持续补充20210306)
光模块目前有两个主流应用场景,电信和数据中心。电信泛指所有的电信相关的基建,比如传输网、接入网、承载网,数据中心有各大运行商自建的数据中心还有大互联网公司自建或者政企相关的数据中心。
电信使用主要是长距离、大容量的工作需求,更多使用相干光模块;
数据中心主要是近距离,多端口的需求,更多使用非相干光模块。
以下转载自https://zhuanlan.zhihu.com/p/101607360
说到光模块,相信大家一定不会觉得陌生。

随着光通信的高速发展,现在我们工作和生活中很多场景都已经实现了“光进铜退”。也就是说,以同轴电缆、网线为代表的金属介质通信,逐渐被光纤介质所取代。
而光模块,就是光纤通信系统的核心器件之一。
光模块的组成结构
光模块,英文名叫Optical Module。Optical,意思是“视力的,视觉的,光学的”。
准确来说,光模块是多种模块类别的统称,具体包括:光接收模块,光发送模块,光收发一体模块和光转发模块等。

现今我们通常所说的光模块,一般是指光收发一体模块(下文也是如此)。
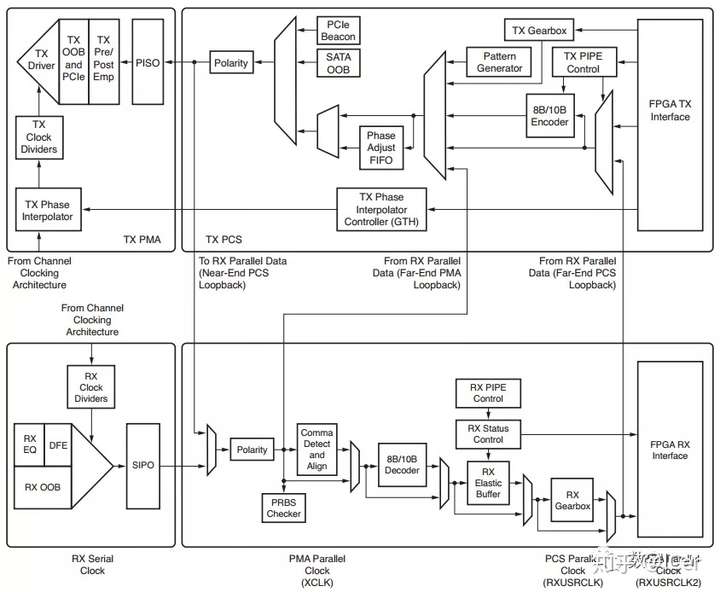
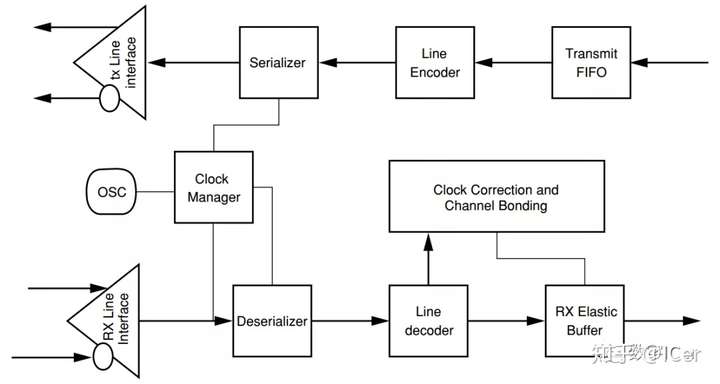
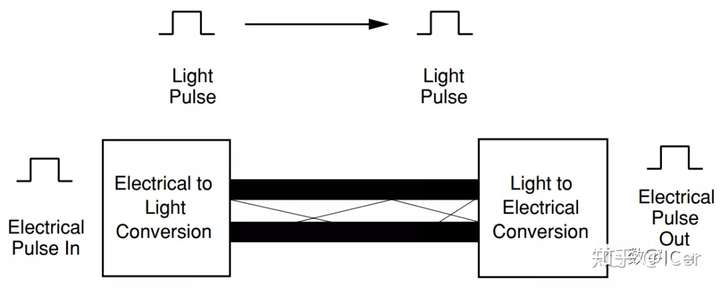
光模块工作在物理层,也就是OSI模型中的最底层。它的作用说起来很简单,就是实现光电转换。把光信号变成电信号,把电信号变成光信号,这样子。

虽然看似简单,但实现过程的技术含量并不低。
一个光模块,通常由光发射器件(TOSA,含激光器)、光接收器件(ROSA,含光探测器)、功能电路和光(电)接口等部分组成。
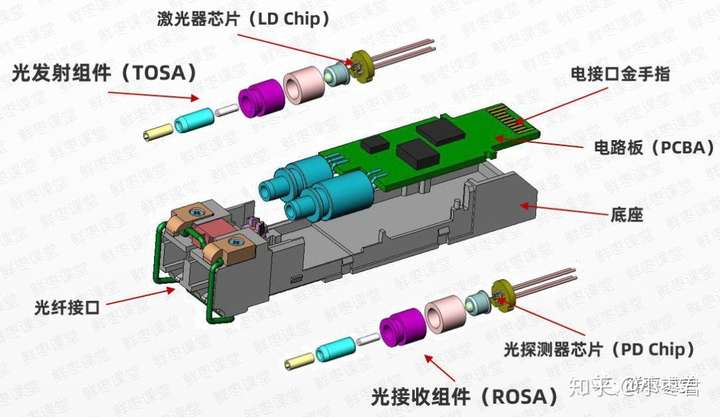
在发射端,驱动芯片对原始电信号进行处理,然后驱动半导体激光器(LD)或发光二极管(LED)发射出调制光信号。
在接收端,光信号进来之后,由光探测二极管转换为电信号,经前置放大器后输出电信号。
光模块的封装
对于初学者来说,光模块最让人抓狂的,是它极为复杂的封装名称,还有让人眼花缭乱的参数。

封装,可以简单理解为款型标准。它是区分光模块的最主要方式。
之所以光模块会存在如此之多的不同封装标准,究其原因,主要是因为光纤通信技术的发展速度实在太快。
光模块的速率不断提升,体积也在不断缩小,以至于每隔几年,就会出新的封装标准。新旧封装标准之间,通常也很难兼容通用。
此外,光模块的应用场景存在多样性,也是导致封装标准变多的一个原因。不同的传输距离、带宽需求、使用场所,对应使用的光纤类型就不同,光模块也随之不同。
小枣君简单罗列了一下包括封装在内的光模块分类方式,如下表所示:
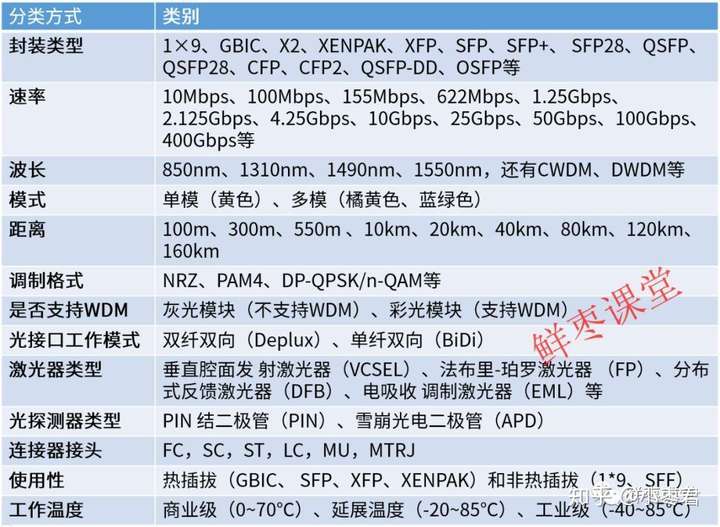
在讲解封装和分类之前,我们先介绍一下光通信的标准化组织。因为这些封装,都是标准化组织确定的。
目前全球对光通信进行标准化的组织有好几个,例如大家都很熟悉的IEEE(电气和电子工程师协会)、ITU-T(国际电联),还有MSA(多源协议)、OIF(光互联论坛)、CCSA(中国通信标准化协会)等。
行业里用的最多的,是IEEE和MSA。
MSA大家可能不怎么熟悉,它的英文名是Multi Source Agreement(多源协议)。它是一种多供应商规范,相比IEEE算是一个民间的非官方组织形式,可以理解是产业内企业联盟行为。
好了,我们开始介绍封装。
首先大家可以看一下下面这张图,比较准确地描述了不同封装的出现时期,还有对应的工作速率。
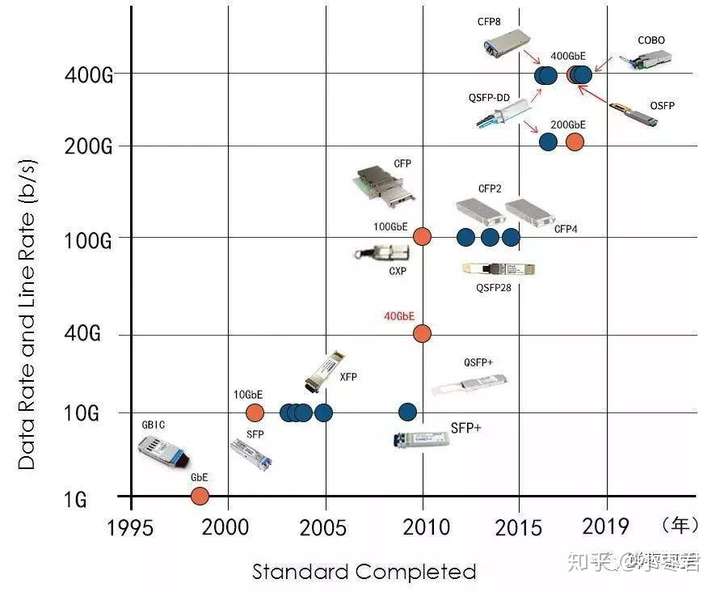
那些太老的或很少见的标准我们就不管了,主要看看常见的封装。
GBIC

GBIC,就是Giga Bitrate Interface Converter(千兆接口转换器)。
在2000年之前,GBIC是最流行的光模块封装,也是应用最广泛的千兆模块形态。
SFP

因为GBIC的体积比较大,后来,SFP出现,开始取代GBIC的位置。
SFP,全称Small Form-factor Pluggable,即小型可热插拔光模块。它的小,就是相对GBIC封装来说的。
SFP的体积比GBIC模块减少一半,可以在相同的面板上配置多出一倍以上的端口数量。在功能上,两者差别不大,都支持热插拔。SFP支持最大带宽是4Gbps。
XFP

XFP,是10-Gigabit Small Form-factor Pluggable,一看就懂,就是万兆SFP。
XFP采用一条XFI(10Gb串行接口)连接的全速单通道串行模块,可替代Xenpak及其派生产品。
SFP+

SFP+,它和XFP一样是10G的光模块。
SFP+的尺寸和SFP一致,比XFP更紧凑(缩小了30%左右),功耗也更小(减少了一些信号控制功能)。

SFP28

速率达到25Gbps的SFP,主要是因为当时40G和100G光模块价格太贵,所以搞了这么个折衷过渡方案。
QSFP/QSFP+/QSFP28/QSFP28-DD

Quad Small Form-factor Pluggable,四通道SFP接口。很多XFP中成熟的关键技术都应用到了该设计中。
根据速度可将QSFP分为4×10G QSFP+、4×25G QSFP28、8×25G QSFP28-DD光模块等。
以QSFP28为例,它适用于4x25GE接入端口。使用QSFP28可以不经过40G直接从25G升级到100G,大幅简化布线难度以及降低成本。

QSFP-DD,成立于2016年3月,DD指的是“Double Density(双倍密度)”。将QSFP的4通道增加了一排通道,变为了8通道。
它可以与QSFP方案兼容,原先的QSFP28模块仍可以使用,只需再插入一个模块即可。QSFP-DD的电口金手指数量是QSFP28的2倍。

QSFP-DD每路采用25Gbps NRZ或者50Gbps PAM4信号格式。采用PAM4,最高可以支持400Gbps速率。
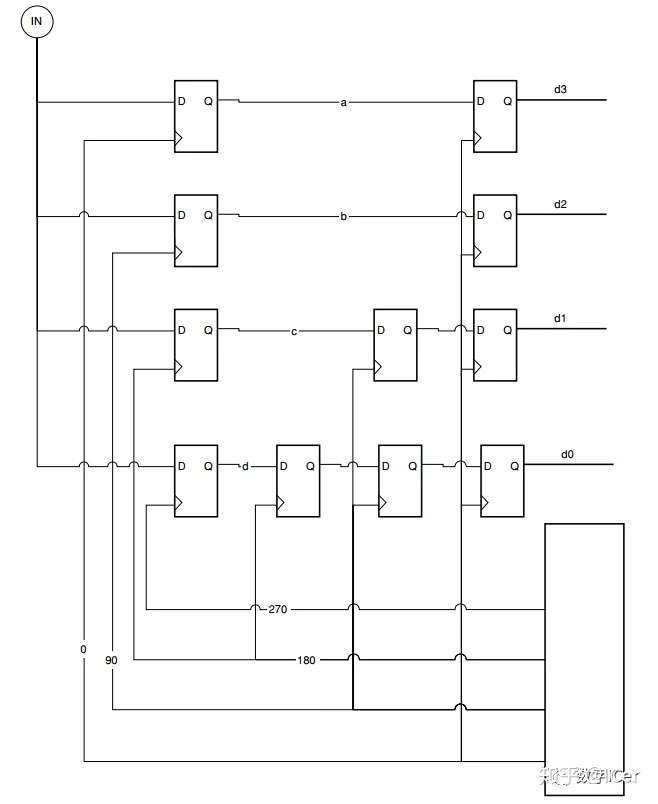
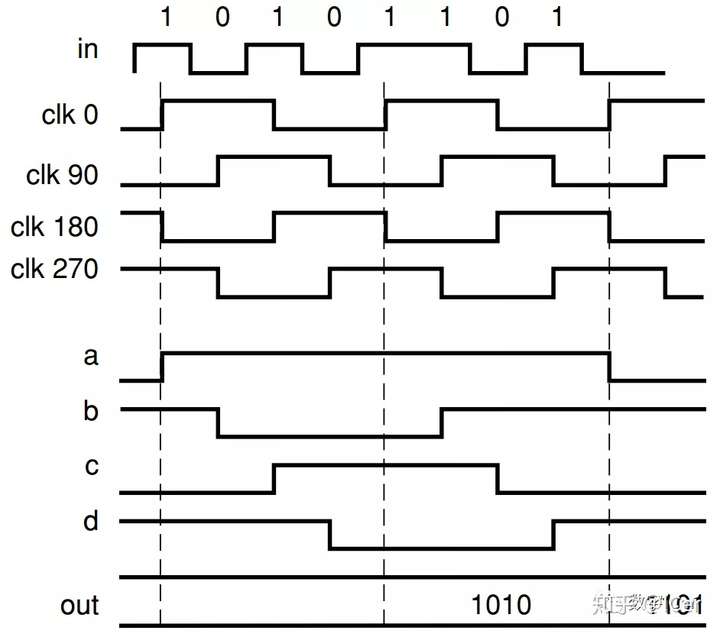
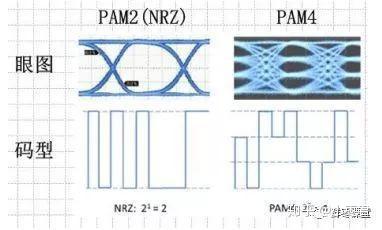
NRZ和PAM4
PAM4(4 Pulse Amplitude Modulation)是一个“翻倍”技术。
对于光模块来说,如果想要实现速率提升,要么增加通道数量,要么提高单通道的速率。
传统的数字信号最多采用的是NRZ(Non-Return-to-Zero)信号,即采用高、低两种信号电平来表示要传输的数字逻辑信号的1、0信息,每个信号符号周期可以传输1bit的逻辑信息。
而PAM信号采用4个不同的信号电平来进行信号传输,每个符号周期可以表示2个bit的逻辑信息(0、1、2、3)。在相同通道物理带宽情况下,PAM4传输相当于NRZ信号两倍的信息量,从而实现速率的倍增。
CFP/CFP2/CFP4/CFP8
Centum gigabits Form Pluggable,密集波分光通信模块。传输速率可达100-400Gbps。
CFP是在SFP接口基础上设计的,尺寸更大,支持100Gbps数据传输。CFP可以支持单个100G信号,一个或多个40G信号。
CFP、CFP2、CFP4的区别在于体积。CFP2的体积是CFP的二分之一,CFP4是CFP的四分之一。
CFP8是专门针对400G提出的封装形式,其尺寸与CFP2相当。支持25Gbps和50Gbps的通道速率,通过16x25G或8×50电接口实现400Gbps模块速率。

OSFP

这个和我们常说的OSPF路由协议有点容易混淆哈。
OSFP,Octal Small Form Factor Pluggable,“O”代表“八进制”,2016年11月正式启动。
它被设计为使用8个电气通道来实现400GbE(8*56GbE,但56GbE的信号由25G的DML激光器在PAM4的调制下形成),尺寸略大于QSFP-DD,更高瓦数的光学引擎和收发器,散热性能稍好。
以上,就是常见的一些光模块封装标准。
400G光模块
大家注意到,刚才介绍封装的时候,小枣君一共提到了3种支持400Gbps的光模块,分别是QSFP-DD、CFP8和OSFP。
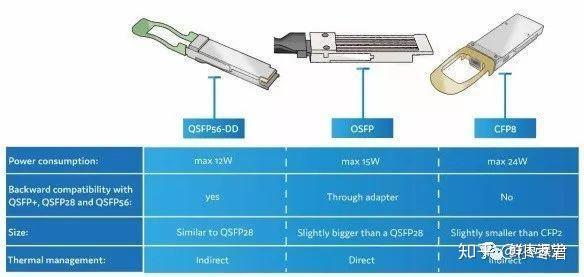
400G,是目前光通信产业的主要竞争方向。现在400G也是规模商用的初期阶段。
众所周知,因为5G网络建设的大规模启动,加上云计算迅猛发展、大规模数据中心批量建设,ICT行业对400G的需求变得越发迫切。
早期的400G光模块,使用的是16路25Gbps NRZ的实现方式,采用CDFP或CFP8的封装。
这种实现方式的优点是可以借用在100G光模块上成熟的25G NRZ技术。但缺点是需要16路信号进行并行传输,功耗和体积都比较大,不太适合数据中心的应用。
后来,开始采用PAM4取代NRZ。
在光口侧主要是使用8路53Gbps PAM4或者4路106Gbps PAM4实现400G的信号传输,在电口侧使用8路53Gbps PAM4电信号,采用OSFP或QSFP-DD的封装形式。
相比较来说,QSFP-DD封装尺寸更小(和传统100G光模块的QSFP28封装类似),更适合数据中心应用。OSFP封装尺寸稍大一些,由于可以提供更多的功耗,所以更适合电信应用。
目前的400G光模块,不管是哪种封装,价格都很昂贵,离用户的期望值还有很大差距。所以,暂时还无法快速进行全面普及。

还有一个值得一提的,是硅基光,也就是经常提到的硅光。
硅光技术在400G时代被认为有广阔的应用前景和竞争力,目前受到很多企业和研究机构的关注。
光模块的关键概念
插播了一下400G,我们回过头来继续说光模块的分类。
在封装的基础上,配合一些参数,就会有光模块的命名。
以100G为例,我们经常会看到的光模块有以下几种:
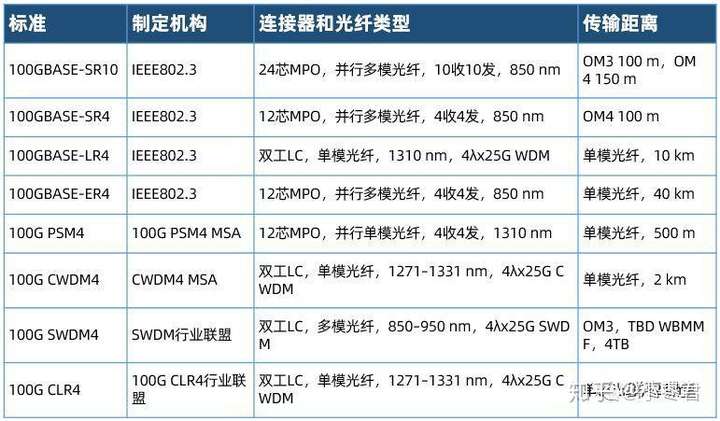
其中100GBASE开头的标准都是IEEE 802.3工作组提出的。PSM4和CWDM4是MSA的。
PSM4(Parallel Single Mode 4 lanes,并行单模四通道)
CWDM4(Coarse Wavelength Division Multiplexer 4 lanes,四通道粗波分复用)
我们看IEEE 802.3的命名:
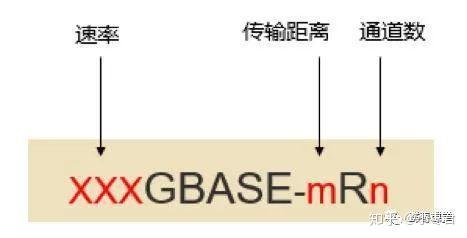
如上图所示:
100GBASE-LR4名称中,LR表示long reach,即10Km,4表示四通道,即4*25G,组合在一起为可以传输10Km的100G光模块。
其中-R的命名规则如下:
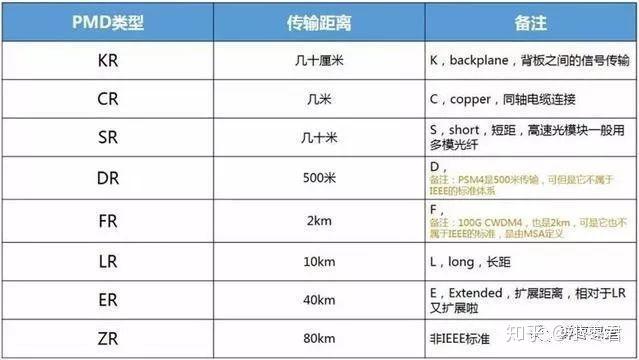
之所以有了IEEE的100GBASE,还会有MSA的PSM4和CWDM4,是因为当时100GBASE-SR4 支持的距离太短,不能满足所有的互联需求,而100GBASE-LR4成本太高。PSM4和CWDM4提供了中距离更好的解决方案。
除了距离和通道数,我们再来看看中心波长。
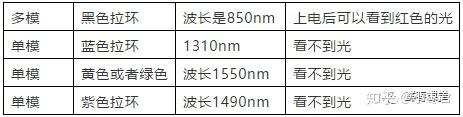
光的波长,直接决定了它的物理特性。目前我们在光纤里使用的光,中心波长主要分为850nm、1310nm和1550nm(nm就是纳米)。
其中,850nm主要用于多模,1310nm和1550nm主要用于单模。
关于单模和多模,以前小枣君介绍光纤的时候详细说过,可以参考这里:光纤光缆的基础知识
对于单模和多模,裸模块如果没有标识的话,很容易混淆。
所以,一般厂家会在拉环的颜色上进行区分:

这里我们顺便提一下CWDM和DWDM,大家应该也经常看到。
WDM,就是Wavelength Division Multiplexing(波分复用)。简单来说,就是把不同波长的光信号复用到同一根光纤中进行传输。
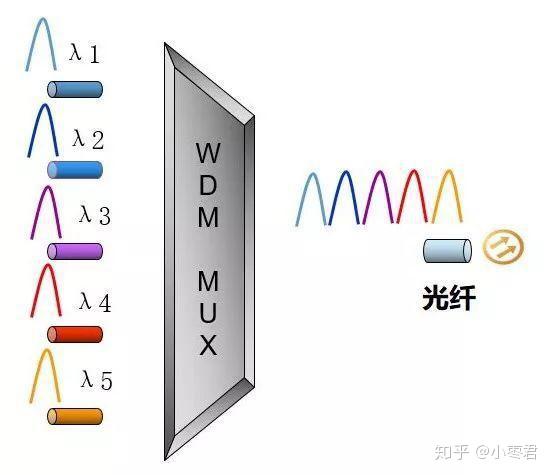
波分复用和频分复用
其实,波分复用就是一种频分复用。波长×频率=光速(固定值),所以按波长分其实就是按频率分。而光通信里面,人们习惯按波长命名。
DWDM,是密集型WDM,Dense WDM。CWDM,就是稀疏型WDM,Coarse WDM。看名字就应该明白,D-WDM里面波长间隔更小。
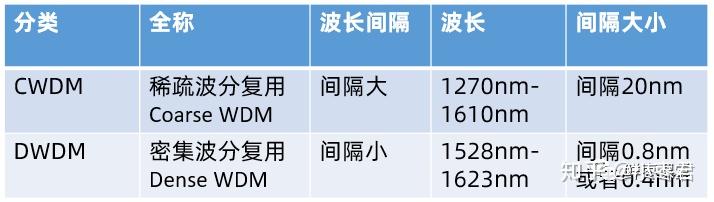
WDM的优点就是容量大,而且它可以远距离传输。
顺便说一下BiDi,这个概念现在也频繁被提及。
BiDi(BiDirectional)就是单纤双向,一根光纤,双向收发。工作原理如下图所示,其实就是加了一个滤波器,发送和接收的波长不同,可以实现同时收发。
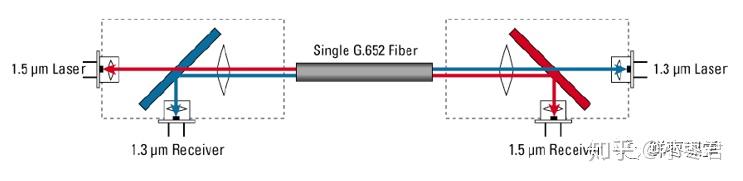

光模块的基本指标
光模块的基本指标主要包括以下几个:
输出光功率
输出光功率指光模块发送端光源的输出光功率。可以理解为光的强度,单位为W或mW或dBm。其中W或mW为线性单位,dBm为对数单位。在通信中,我们通常使用dBm来表示光功率。
光功率衰减一半,降低3dB,0dBm的光功率对应1mW。
接收灵敏度最大值
接收灵敏度指的是在一定速率、误码率情况下光模块的最小接收光功率,单位:dBm。
一般情况下,速率越高接收灵敏度越差,即最小接收光功率越大,对于光模块接收端器件的要求也越高。
消光比
消光比是用于衡量光模块质量的重要参数之一。
它是指全调制条件下信号平均光功率与空号平均光功率比值的最小值,表示0、1信号的区别能力。光模块中影响消光比的两个因素:偏置电流(bias)与调制电流(Mod),姑且看成ER=Bias/Mod。
消光比的值并非越大光模块越好,而是消光比满足802.3标准的光模块才好。
光饱和度
又称饱和光功率,指的是在一定的传输速率下,维持一定的误码率(10-10~10-12)时的最大输入光功率,单位:dBm。
需要注意的是,光探测器在强光照射下会出现光电流饱和现象,当出现此现象后,探测器需要一定的时间恢复,此时接收灵敏度下降,接收到的信号有可能出现误判而造成误码现象,而且还非常容易损坏接收端探测器,在使用操作中应尽量避免超出其饱和光功率。
光模块的产业链
最后我们简单说一下光模块的产业链。
目前光模块的市场很火,主要原因前面说过了,因为5G和数据中心。
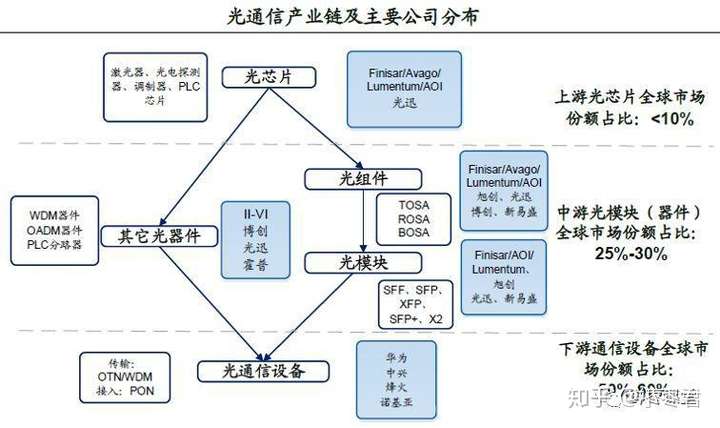
整个5G网络建设,最花钱的地方有两个,一个是基站,还有一个就是光承载网。光承载网里面,光纤的水份不多,但是光模块比较让人头大。

光模块里面,最贵的是芯片。激光器和光探测器里面的芯片,占了一半以上的成本。
而芯片这块,目前的现状是:国外厂商在高端芯片上占据优势,国内厂商在中低端芯片占有优势。但国内厂商在不断向高端市场进行突破。高端芯片的利润率高于低端,这个是显然的。
从整体上来看,中国光通信企业有超过1000家,但利润率都非常低。而且,在产业链格局上,面对设备商(华为、中兴),光通信企业也比较“卑微”,没有什么议价能力。
行业竞争激烈,新产品、高端产品,利润较多,但时间一长,利润就会缩水。
反正大概就是这么个情况。
关于产业链的具体情况,因为5G的原因,现在券商们非常关注,也输出了很多的相关报告,大家可以自行搜索阅读一下。
好啦,以上就是今天文章的所有内容。感谢大家的耐心观看,我们下期再见!
参考文献:
1、《光模块行业深度报告》,德邦证券
2、《5G承载光模块白皮书》,IMT2020推进组
3、《对于100G光模块,你了解多少》,专说光通信
4、《产业图解:5G(光模块)》,佚名