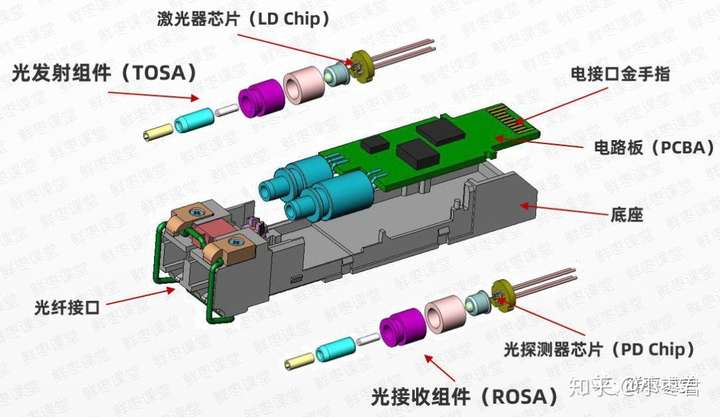
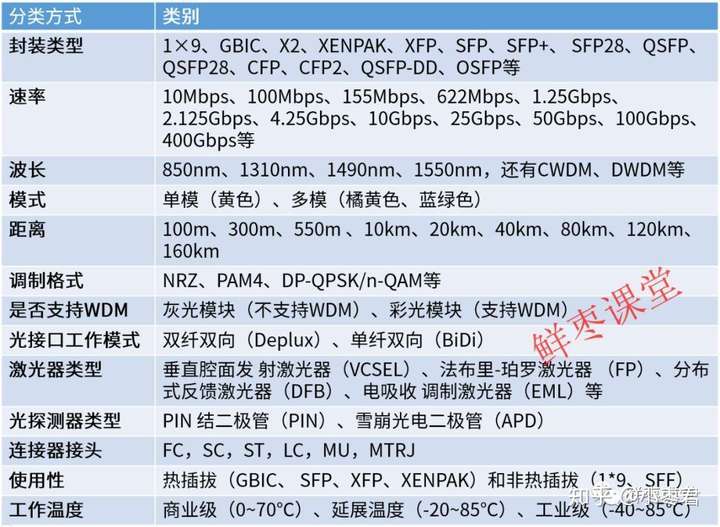
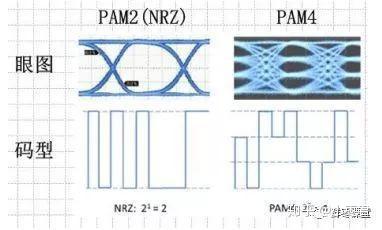
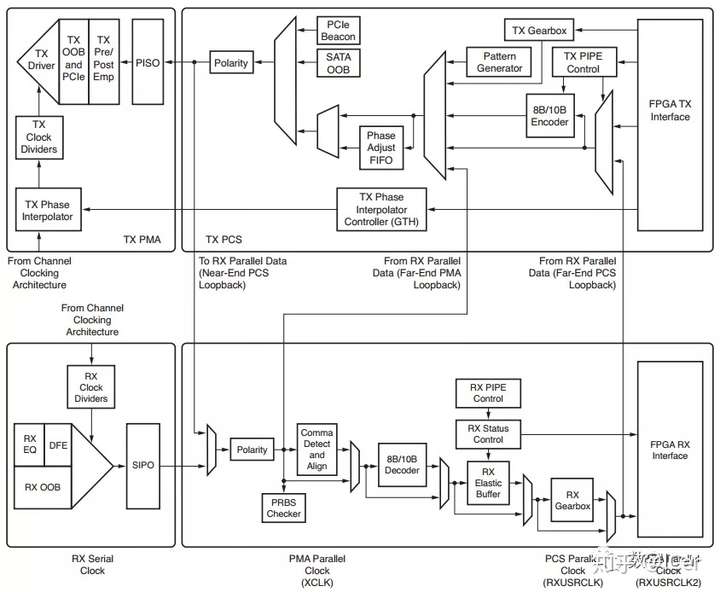
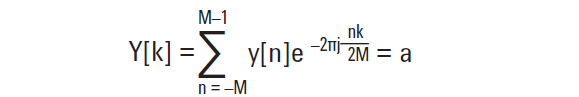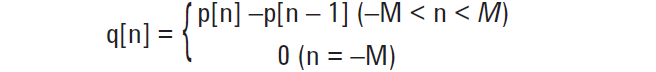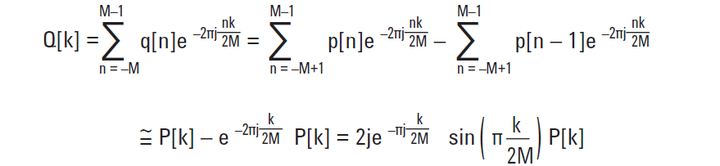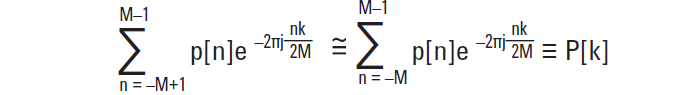[转载]如何评估示波器的信号完整性
您是否正在评测一台新的示波器,希望确保它能够在广泛的频率范围内全面而精确地显示被测信号?如果是,您所选的示波器就必须具备信号完整性的所有促成因素: 高分辨率、低固有噪声、平坦的频率响应和适当的 ENOB。
电子测试中经常会提到示波器“信号完整性”,这是衡量信号质量的重要指标。随着带宽范围提升,查看小信号或大信号的细微变化的需求增加,示波器自身的信号完整性的重要性已进一步提升。为什么信号完整性被视为示波器的关键指标? 信号完整性对示波器整体测量精度的影响非常大,它对波形形状和测量结果准确性的影响会出乎您的想象。示波器性能取决于其自身信号完整性的良莠,比如说信号失真、噪声和损耗。自身的信号完整性高的示波器能够更好地显示被测信号的细节;反之,如果自身的信号完整性很差,示波器便无法准确反映被测信号。示波器自身信号完整性方面的差异直接影响到工程师能否高效地对设计进行深入分析、理解、调试和评估。示波器的信号完整性不佳,将对产品开发周期、产品质量以及元器件的选择带来巨大风险。要避免这种风险,只有通过比较和评测,选择一台具有出色信号完整性的示波器才是解决之道。
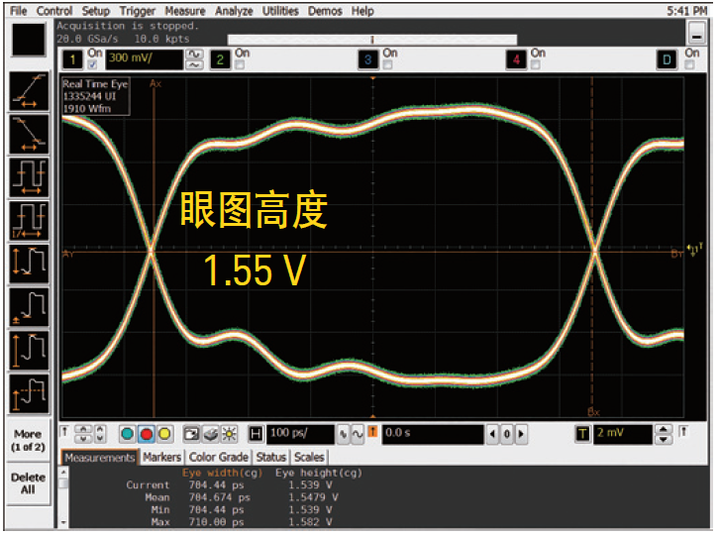
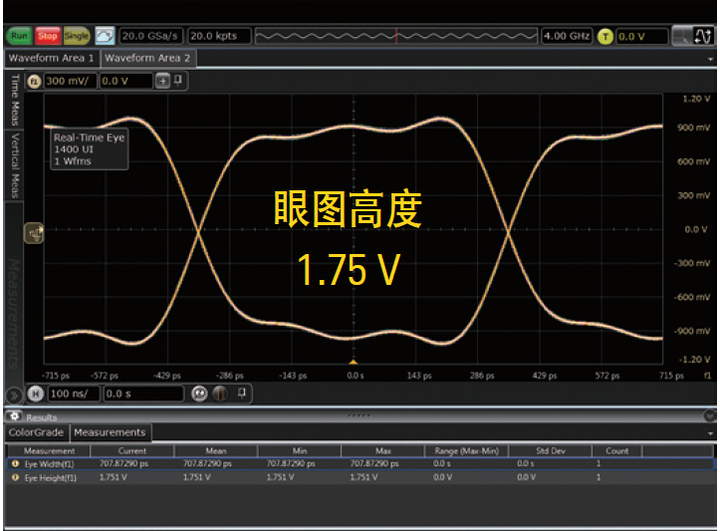
图1(a). 即便是同品牌同带宽的示波器产品, 信号完整性水平也各有高低。这里是两款4 GHz 带宽示波器测试同一个信号的眼图。两款示波器的带宽、垂直/水平设置完全相同。您可以看到, 右图 Infiniium S 系列示波器更真实地再现了信号的眼图, 眼图高度比左图DSO9404A 高200 mV。优异的信号完整性能够更精确地再现被测信号的参数值和形状。
信号完整性的构成要素十分复杂,本应用指南将为您庖丁解牛,逐一分解,文中提到的原理适用于所有示波器。针对某些构成要素,我们会以Infiniium S 系列 500 MHz 至 8 GHz 带宽的示波器为例,详尽阐述。
示波器的各个属性彼此配合,相互影响,我们必须从全局角度加以考量。许多示波器品牌所宣传的分辨率、 本底噪声、抖动等技术指标都被冠以了”最佳” 字眼。然而,滴水难成海,独木不成林。您必须清醒地认识到,要提供最佳的信号显示,绝不是仅凭单个最佳技术指标就能实现的。所以在选择示波器时, 只有做到全盘兼顾才能做出最正确的选择。只关注信号完整性的一个方面而忽视其他属性,就好比只见树木不见森林,很有可能会导致错误判断。
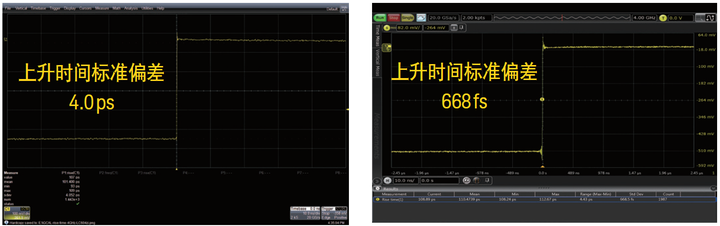
图 1 (b). 请注意: 两款示波器测得的上升时间标准偏差有所不同, 尽管它们的带宽(4 GHz)、采样率(20 GSa/s) 和其他设置都是相同的。在快速上升时间测试中, Infiniium S 系列测得的标准偏差是668 fs (飞秒), 而左边示波器测得的标准偏差为4 ps (皮秒), 偏差是S 系列示波器的6 倍。测量同一个信号的上升时间, 所得的标准偏差越低, 就表明示波器自身的信号完整性越出色, 水平系统的性能也就越高。
ADC 位数和最小分辨率
模数转换器 (ADC) 是确保示波器自身信号完整性的关键技术。ADC 位数与示波器的分辨率成正比。理论上讲,10 位ADC 示波器的分辨率比 8 位ADC 示波器高 4 倍。同理,12 位ADC 示波器相对于10 位ADC 示波器也是如此。图2 以10 位 ADC Infiniium S 系列示波器为例,实际验证了上述结论。

图 2. 多数示波器都是采用 8 位 ADC, 而 S 系列示波器采用的是 40 GSa/s 10 位ADC, 分辨率提升了四倍。
分辨率是指由示波器中的模数转换器(ADC) 所决定的最小量化电平。8 位ADC 可将模拟输入信号编码为 28 = 256 个电平,即量化电平或Q 电平。ADC 在示波器量程内工作,因此在电流和电压测量中,量化电平的步长与示波器的量程设置有关。如果垂直设置为 100mV/格,则量程等于 800 mV (8 格x 100 mV/格),量级电平分辨率就是3.125 mV (即,800 mV 除以256 个量化电平)。
我们现在看一个具体示例: 图 3 中, 两款示波器都已设置为800 mV 全屏显示。8 位ADC 示波器的分辨率是 3.125 mV,即,800 mV 除以 28 (256 个量化电平)。10 位ADC 示波器的分辨率是0.781 mV,即,800 mV 除以 210 (1024 个量化电平)。计算出来的分辨率又被称作最小量化电平,在正常采集模式下,是示波器能识别的信号最小变化范围。
示波器通常支持高分辨率采集模式,在该模式下,要得到正确的信号,示波器的模拟前端要能够防混叠,且采样率远大于实际需要的采样率。也有的厂家采用过采样技术配合DSP 滤波器来提高示波器的垂直分辨率,然后给出一个指标,说高分辨率模式下, 其位数是多少。以Infiniium S系列示波器为例,其 ADC 固有分辨率是10 位,高分辨率模式下是12 位。高分辨率模式要求ADC 实际支持的采样率远高于被测信号测量所需的硬件带宽。
提升分辨率,可以选择更高位数的ADC,同时示波器的垂直刻 度选择范围要更宽。
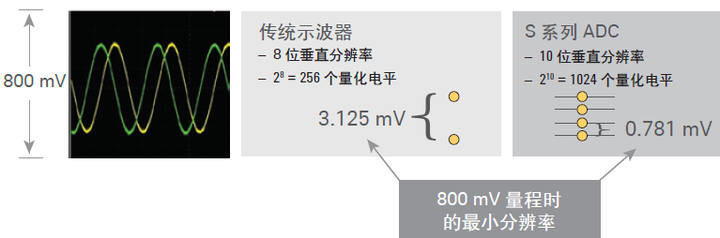
图3. 示波器分辨率是信号完整性的一个重要属性。提高ADC 位数或设置恰当的量程都能改进分辨率。
量程设置对示波器分辨率的影响
量程设置对示波器的分辨率利用程度影响很大。启用模数转换器(ADC) 首先需要设置垂直刻度并尽可能全屏显示波形。举个例子,假如被测信号波形占据示波器屏幕的½,那么 8 位ADC 实际被使用的位数就降到了7 位。又假设波形只占屏幕的¼,那么ADC 实际被使用的位数就从 8 位降至 6 位。如果将波形放大到占据整个屏幕,示波器ADC 的 8 位分辨率就可以得到最充分利用。要获得最佳分辨率,就必须使用最灵敏的垂直刻度设置, 在显示屏上尽可能接近满屏显示波形。
ADC、示波器前端架构及使用的探头决定了示波器硬件能够支 持将垂直量程设置降到多低。所有示波器的垂直刻度设置都有一个极限点,超过这个点,硬件不再起作用,这时,即使用户继续使用旋钮将垂直刻度设置变得更低,也不会改进分辨率, 因为这时用的是软件放大功能。示波器厂商通常将这个点作为转折点,在此之后,即使将示波器的垂直刻度设置得更小,也只能在显示效果上放大信号,但无法像用户期待的那样提高分辨率,因为这时示波器是用软件放大波形。传统示波器在垂直量程设置降至 10mV/格以下,就会启用软件放大功能。另外,部分厂商的示波器会在较小的垂直刻度设置(通常是 10 mV/格以下) 时,自动将示波器带宽限制为远低于标称带宽的一个值。因为这些示波器的前端噪声过于明显,几乎不可能在全带宽上查看小信号。
我们现在对比一下两款示波器。小信号具有一定的幅度,当示波器垂直设置设为16 mV 全屏时,它会占据几乎全屏的空间。
- Infiniium 9000 系列示波器等传统示波器硬件支持的最小刻度是7 mV/格, 低于该设置的垂直刻度, 是用软件放大实现的, 7 mV/格的设置意味着量程是 56 mV (7 mV/格x 8 格), 该示波器采用了8 位ADC, 量化电平数是256, 因此其最小分辨率为218 uV。
- Infiniium S 系列示波器采用了10 位ADC, 硬件支持的最小垂直刻度是2 mV/格, 并且该设置支持满带宽。2 mV/格设置对应的量程为 16 mV (2 mV/格x 8 格), 因此分辨率为 16 mV/1024, 即为15.6 uV — 是传统的8 位示波器的14 倍(参见图4)。
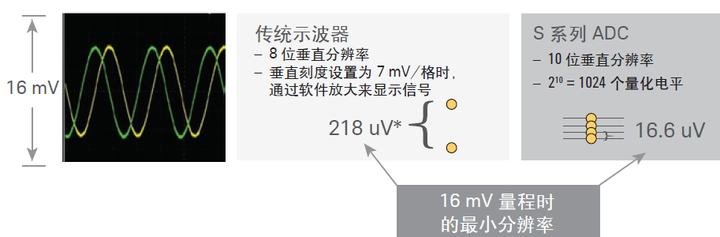
图 4. 查看小信号细节时, 示波器硬件所支持的最小量程是一个关键指标, 决定了您能否查看信号的最小分辨率。
示波器噪声
要想查看低电流和电压值或是大信号的细微变化,您应当选择具备低噪声性能(高动态范围) 的示波器。
注: 您无法查看低于示波器本底噪声的信号细节。
如果示波器本底噪声电平高于ADC 的最小量化电平, 那么ADC的实际位数就达不到其标称位数应达到的理想性能。
示波器的噪声来源包括其前端、模数转换器、探头、电缆等, 对于示波器的总体噪声而言,模数转换器本身的量化误差的贡献通常较小,前端带来的噪声通常贡献较大。
大多数示波器厂商会在示波器出厂之前对其进行噪声测量,并将测量结果列入到产品技术资料中。如果您没有找到相应信息,您可以向厂商索要或是自行测试。示波器本底噪声测量非常简单,只需花上几分钟即可完成。首先,断开示波器前面板上的所有输入连接,设置示波器为 50 Ω 输入路径。您也可以选择 1MΩ 路径。其次,设置存储器深度,比如 1 M 点,把采样率设为高值,以得到示波器全带宽。最后,您也可以打开示波器的无限余辉显示,以查看测得波形的粗细。波形越粗,示波器的本底噪声越大。
示波器通道在每个垂直量程设置上的噪声属性各有不同。波形粗细可以直观反映示波器在该特定设置下的噪声大概范围,准确测量应通过Vrms 交流测量来量化分析噪声情况。您可以将测量结果绘制成噪声图,以便进一步分析(图 7)。这些测量结果反映了每个示波器通道在不同垂直刻度设置下的噪声值,这决定着您所测得的电压数值的误差变化范围。示波器的本底噪声不仅影响电压测量,也影响水平参数的测量精度。
示波器的噪声越低,测量精度就会越高。

图 5. Infiniium S 系列示波器结合使用低噪声前端和 10 位ADC, 可将噪声减少到一半。
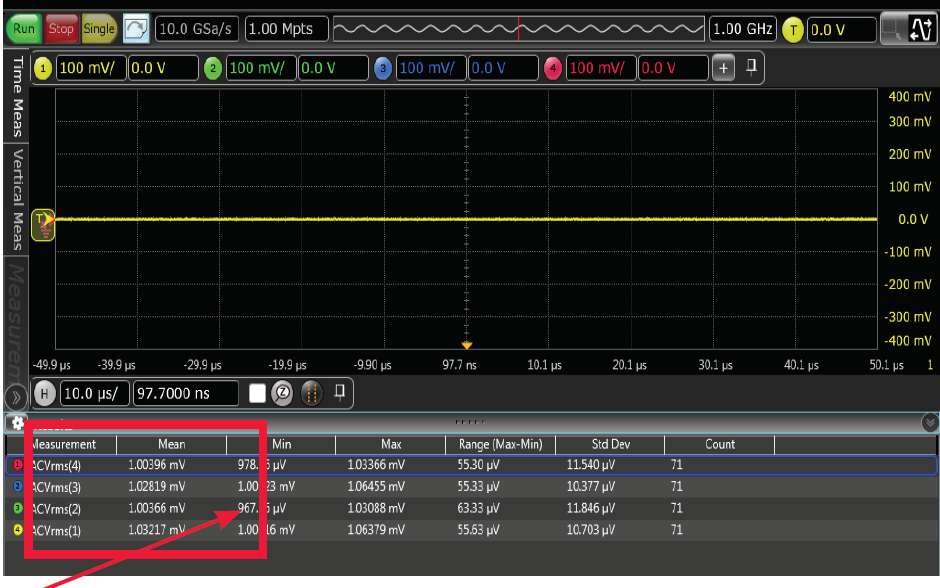
图6. 您能够查看示波器的噪声量, 只需断开示波器的所有输入连接, 并测量每个垂直量程设置下的噪声(电压真有效值)。本例中, 每通道的噪声都是仅为
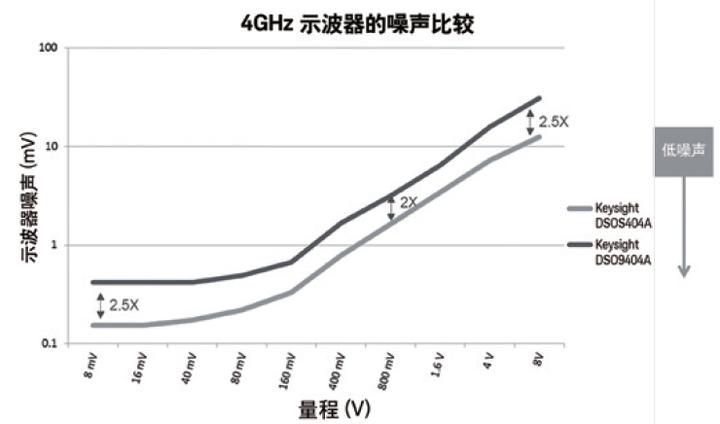
图7. 您可以比较不同厂商的示波器的本底噪声。
图中示例是两款同带宽(4 GHz) Infiniium 示波器的本底噪声在不同量程设置下的对比。示波器的噪声越低, 您就能获得越高的信号完整性。
频率响应
每个示波器型号都有自己的频率响应曲线,它是用来 衡量示波器在额定带宽内采集信号准确性的重要参数。精确采集波形必须满足三个条件。
- 示波器的频响曲线必须平坦。
- 示波器的相位响应曲线必须平坦。
- 被测信号的关键频谱成分必须在示波器的带宽范围内。
上述三个条件缺一不可,否则会导致示波器无法精确采集和再现波形。偏离上述要求越大就意味着测量误差会越大。
任何被测信号都可看成是多次谐波的叠加,每个谐波对应一个频率,示波器的使用者当然希望示波器能够准确测量每个谐波成份的幅度。理想情况下,示波器在其带宽范围内应该有平坦的幅度响应,并且针对每个频点上的信号时延 (相位) 都相等。频率响应平坦,意味着信号在通过示波器内部通道时会产生相同的时延,相同的幅度放大或缩小;如果相位响应不平坦,示波器显示的波形将会是失真的。
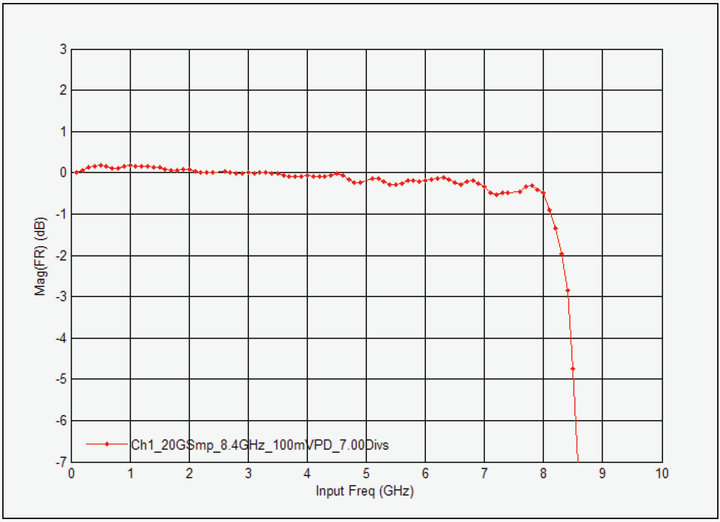
图8. 每个示波器都有自己独特的频率响应。频率响应是否平坦对于信号完整性至关重要。砖墙式频响示波器的带外噪声最低, 而高斯频响的边沿振铃最低。图中显示了 8 GHz 带宽示波器Infiniium DSOS804A 的幅度响应。垂直标度已放大到1 db/格, 8 GHz 带宽内的频响幅度变化十分轻微。
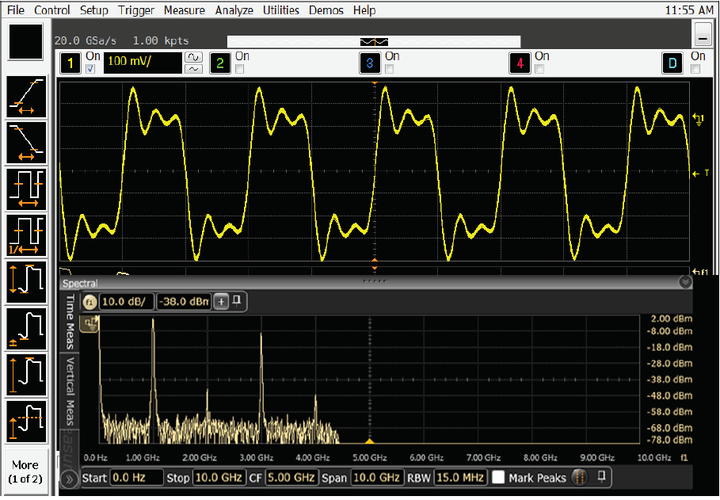
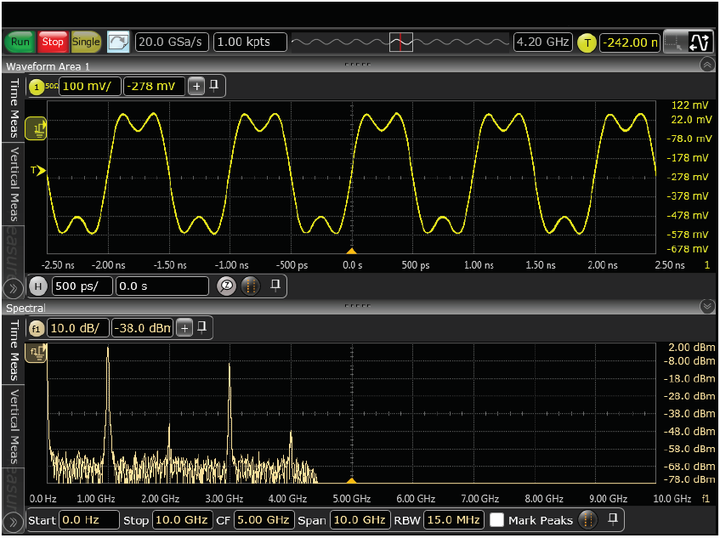
图 9. 两款示波器测试的是同一个信号, 它们的额定带宽、采样率及其他设置均相同。右图中的波形精确地再现了被测信号的各个频谱分量, 但左图中的波形却没有。为什么有这种区别? 这是因为, 右图中的示波器采用了校正滤波器, 幅度和相位响应是平坦的, 而左图中的示波器则不然。
示波器的频率响应不平坦会导致显示出的信号失真。您在选购示波器时,可以向厂商索取频率响应数据。厂商一般不会在示波器技术资料中附带频率响应图,但通常可以根据您的要求来提供。为了方便起见,下面为您展示了各型号Infiniium S 系列示波器的频率响应图。图中设置如下: 20 GSa/s 最大采样率;100 mV/格de 垂直标度;信号幅度占据屏幕7.2 格。
示波器的整体频率响应受两个因素约束,一个是示波器自身的频率响应,另一个是所用探头或电缆的频率响应。如果您使用的是一根1.5 GHz 带宽的BNC 电缆,那么系统的整体带宽瓶颈就是这根BNC 电缆,而不是示波器。探头和与探头相连的附件也是如此。由于探头和电缆本身也具有频率响应,所以您需要设法保证探头、附件以及电缆不会给示波器系统带来限制,以便使用示波器进行精确测量。
500 MHz DSOS054A 示波器的幅度响应
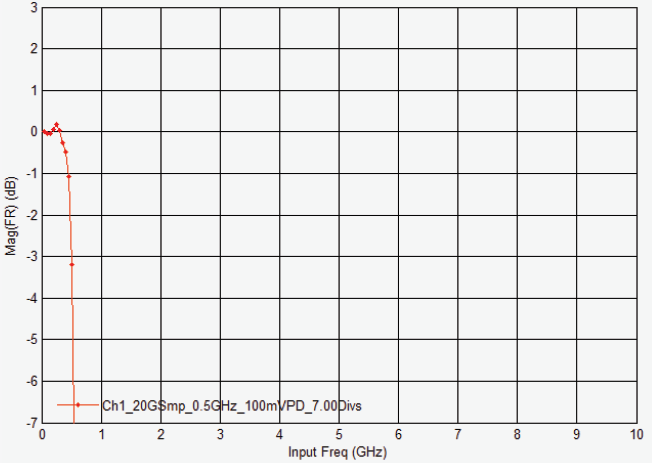
1 GHz DSOS104A 示波器的频率响应
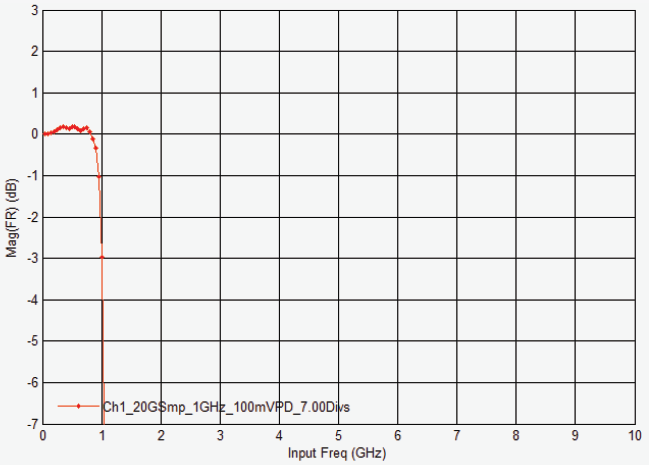
2 GHz DSOS204A 的幅度响应
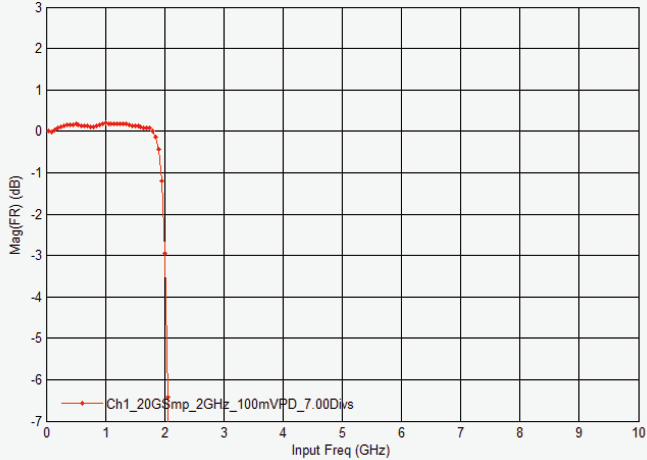
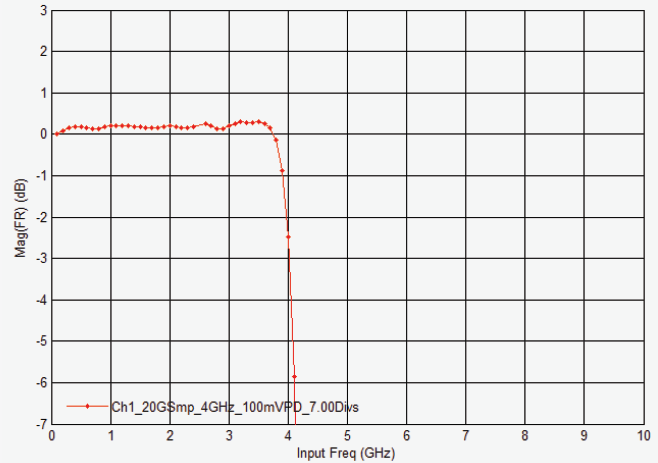
4 GHz DSOS404A 示波器的幅度响应
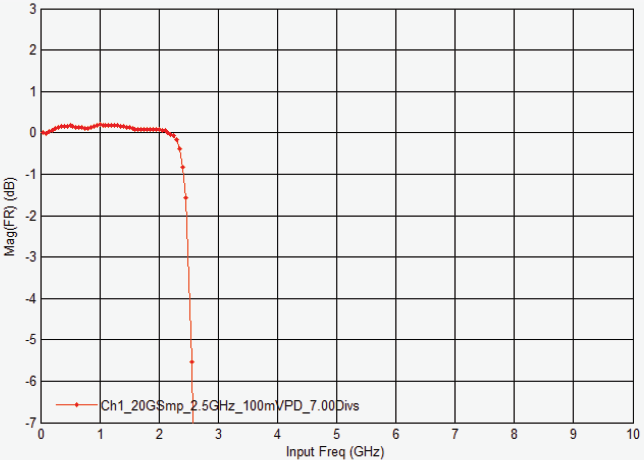
4 GHz DSOS404A 示波器的幅度响应
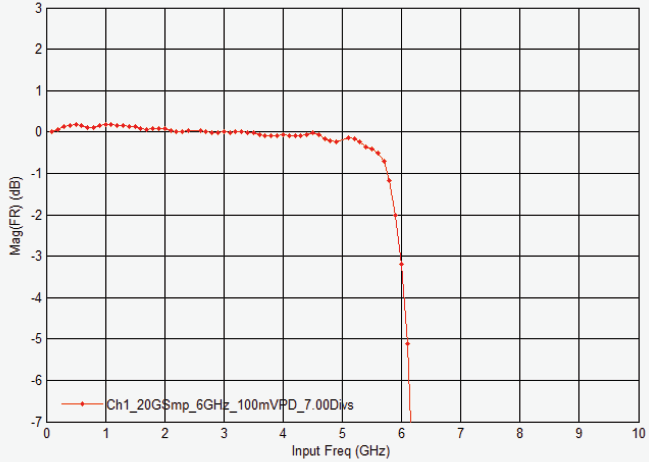
6 GHz DSOS604A 示波器的幅度响应
校正滤波器
有些示波器的频率响应完全是由其模拟前端滤波器决定的;另一些示波器的频响则是由模拟前端和实时校正滤波器共同决定。实时校正滤波器通常是用硬件 DSP 实现的,并且会针对不同示波器家族略有调整,目的是保证幅度和相位响应是平坦的。由于不存在完美的模拟前端滤波器,所以将实时校正滤波器与模拟前端滤波器的组合使用,示波器的幅度和频率相位响应更加平坦。在业内,较高质量的示波器一定会使用校正滤波器配合模拟前端滤波器,以保证频响的平坦度。
频率响应的形状通常借助其滚降特征来体现。砖墙式频响最受青睐,这是因为该频响对带外噪声抑制力最强。需要注意一种极端情况,即被测信号的边沿速度很快,超过了示波器带宽的测量能力时,砖墙式频响测得的波形有可能伴有轻微的欠冲和过冲现象。使用高斯频响的示波器来测量,显示的振铃会小很多,但缺点是带外噪声较大。
软件滤波器
除了硬件实现的实时校正滤波器之外,示波器还可以通过纯软件滤波方法增强示波器系统的频响平坦度。软件带宽滤波器的速度当然远比不上硬件滤波器,而且要求示波器采用最大采样率以避免信号混叠现象。相对于等效的硬件或模拟滤波器,这种软件滤波器的信号完整性有可能不是最好的。但是,软件滤波器的优点在于灵活性较大。
例如,Infiniium PrecisionProbe 应用软件就是一款软件滤波器。该软件通过去除通道、探头或电缆的影响,来提高信号完整性。另外,它使用具有极快边沿的内部校准信号,仅需两分钟时间就能表征探头或电缆的 S21 参数。根据表征结果,软件在滚降点上产生反相的滤波器,从而可以去除BNC 电缆带来的信号损耗误差。
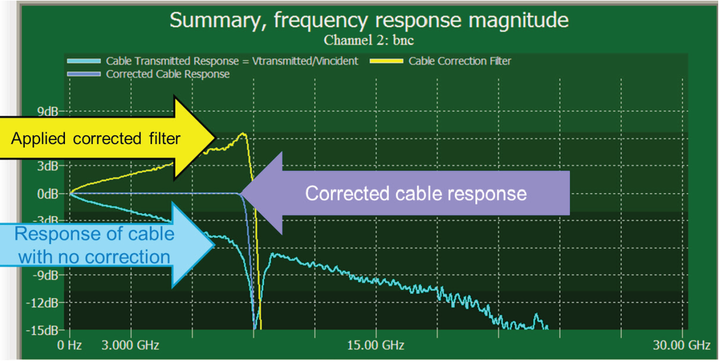
图10. Infiniium PrecisionProbe 应用软件充分体现了软件带宽滤波器的灵活性, 它能够帮助工程师快速确定电缆或探头的频率响应, 进而校正这个系统的频响, 去除电缆或探头带来的信号损耗误差。
ENOB (有效位数)
有效位数(ENOB) 是示波器动态性能的重要计量指标。尽管某些示波器厂商会提供示波器ADC 本身的ENOB 指标,但这一数值没有意义。整个示波器系统的 ENOB 指标才有意义。倘若示波器前端噪声过大,即便ADC 具有较高的ENOB,整个测量系统的 ENOB 也会明显下降。一般情况下,示波器厂商不提供总体ENOB 值,但他们可根据用户的要求,针对某个示波器型号进行表征并提供ENOB。
ENOB 不是具体的数值,而是借助一系列曲线进行描述。ENOB 是通过对固定幅度的正弦波信号进行扫频而测得;特定的垂直刻度设置都对应一条ENOB 曲线,随着频率的变化而变化。示波器可以捕获分析和测试电压测量结果。时域分析法是用测得的数据减去理论上的最佳正弦波数据计算得出ENOB。ENOB 曲线误差可能来自于示波器的前端,比如不同频率下相位的非线性和幅度变化,还有可能来自于ADC 内插复用造成的失真。对相同的信号,我们也可以用频域测量法,根据主频功率和该主频以外的宽带范围内的功率来计算ENOB。两种方法得到的结果是 相同的。
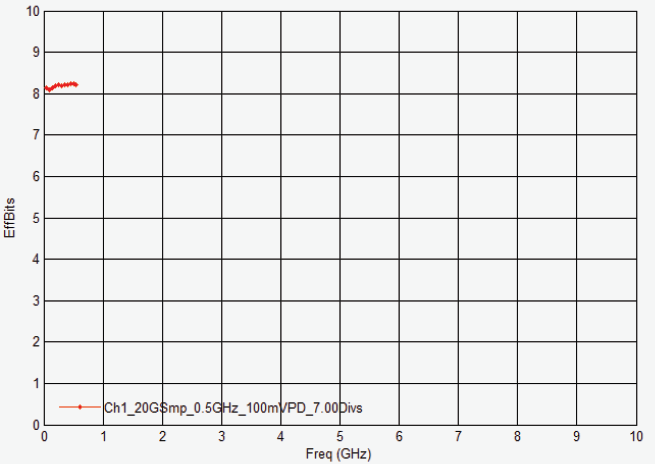
示波器的系统 ENOB 会比 ADC 自身的 ENOB 要低。例如,8 位Infiniium 9000 系列 1 GHz 带宽示波器的ENOB 约为 6.5。1 GHz DSOS104A 示波器配备 10 位 ADC 和超低噪声前端,其系统ENOB 约为 8。为了加深您对ENOB 的理解,接下来我将会附上几个Infiniiuum S 系列示波器的ENOB 图,其中被测信号占据屏幕的7.2 格、最大采样率为20 GSa/s。
500 MHz DSOS054A 示波器的ENOB 图
1 GHz DSOS104A 示波器的ENOB 图
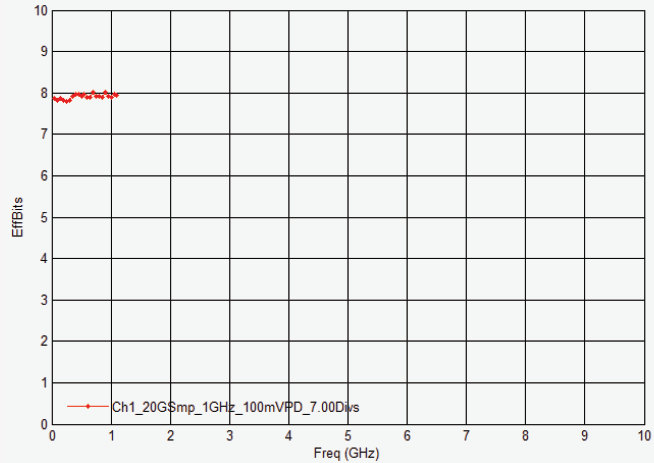
2 GHz DSOS204A 示波器的ENOB 图
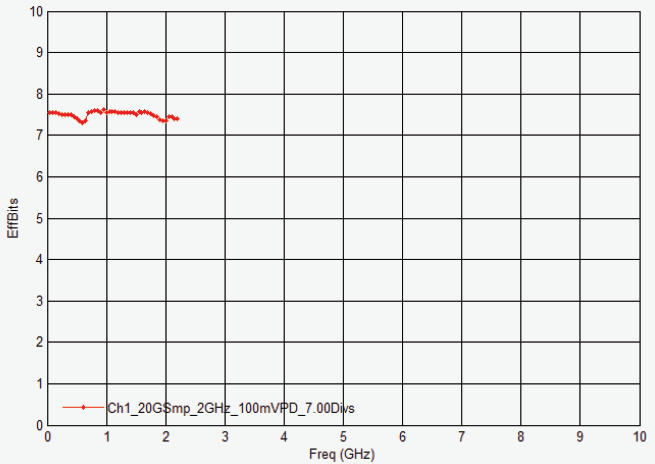
2.5 GHz DSOS254A 示波器的ENOB 图
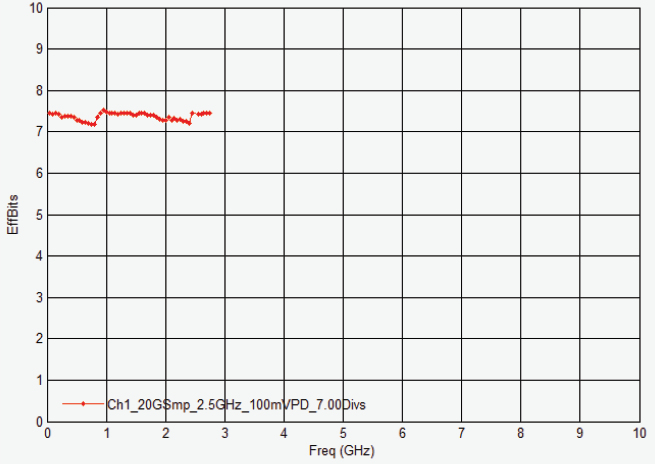
一般来说,ENOB 越高越好。但是,我们不能把它作为评估信号完整性好坏的唯一指标。ENOB 没有考虑到示波器的偏置误差或相位失真等因素。这一点必须引起工程师的高度重视。
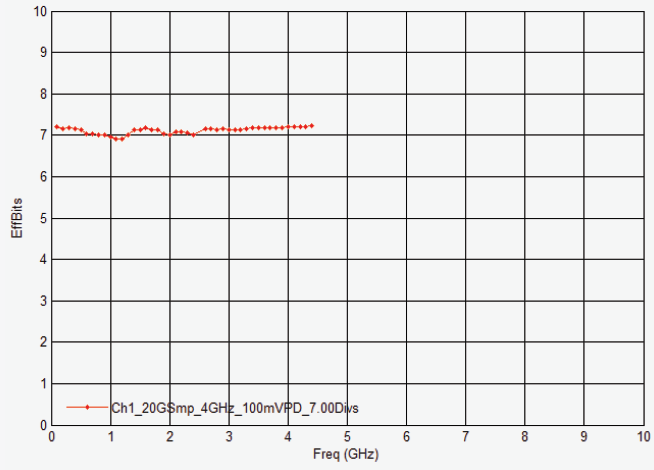
4 GHz DSOS404A 示波器的ENOB 图
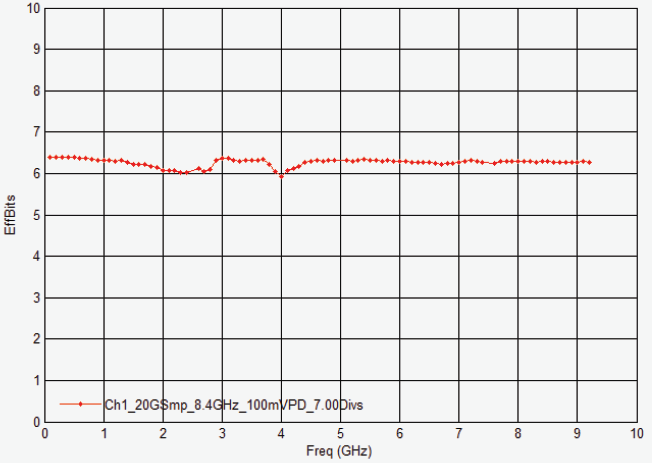
8 GHz DSOS804A 示波器的ENOB 图
固有抖动
抖动是指信号边沿对理想位置的偏移,以ps rms 或ps pp 为单位。抖动通常出现在高速数字系统中,它的来源有很多种,包括晶振产生的热噪声和随机机械噪声。另外,轨迹、电缆和连接器中存在的符号间干扰也会给系统增添额外的抖动。过多的抖动是系统无法接受的,因为抖动会造成计时违规,从而导致系统操作失常。例如,通信系统存在过多抖动就会产生不可接受的比特误码率(BER),从而造成信号传输错误。因此,要确保高速数字系统的可靠性,您就必须执行抖动测量。
在测量之前,您首先要了解示波器的抖动测量功能,以及对测量结果的解析能力。具体地说,示波器首先对数字波形进行采样并存储。每个波形都是由一组采样点构成。理想情况下,示波器能够采集采样点等间距的波形。但在实际应用中,示波器的内部电路缺陷会使ADC 采样点水平偏移理想位置,这种偏移就是示波器自身固有的本底抖动。因此在抖动测量中,示波器无法分辨哪些抖动是来自被测器件或是示波器本身。
理想情况下,使用示波器对一个无抖动的理想信号进行抖动测量,得到的抖动值应当为零。但是,我们必须要考虑示波器本身的抖动。示波器抖动的来源有多个方面,包括: 多片ADC 进行内插带来的误差,ADC 采样时钟输入信号的抖动,以及其他内部抖动源。这种水平偏移误差源的集合会构成一个总的水平时间误差,即等效的采样时钟抖动(简称为采样时钟抖动),也可以 叫做固有源抖动时钟(SJC)。示波器厂商将其精简为术语”固有 抖动”,用于表示示波器在短时间内的最低固有抖动。
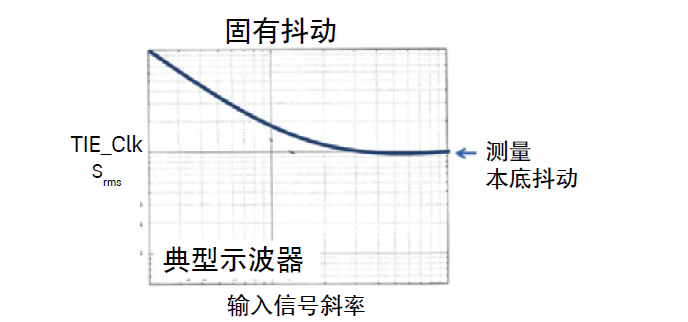
测量本底抖动 = 函数(噪声、信号斜率、固有抖动)
即便对无抖动的理想信号进行测量,示波器的抖动测量结果也不会为零。”本底抖动” 表示示波器对一个无抖动的理想信号进行抖动测量的结果。本底抖动的构成不仅包括上述提到的采样时钟抖动,而且还包括垂直误差源产生的抖动,例如垂直噪声和混叠的信号谐波。垂直误差源能够影响水平时间测量,因为它们可以改变阈值交叉点。
与水平精度相关的示波器电路被称为时基,用于确保时标精度和抖动水平分量。时基电路设计得好的示波器,固有抖动值有机会更低,因为水平系统的抖动贡献少了。

图11. Infiniium S 系列示波器添加了新的时基模块。
时钟精度高达75 x 10-9。固有抖动低于130 fs (短期固有抖动)。
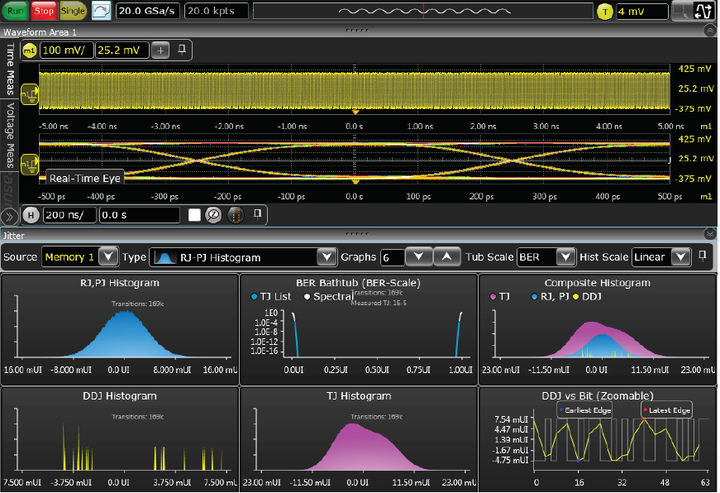
图12. 使用Infiniium S 系列示波器测量实际抖动。
所有型号采用相同的时基技术模块, 测得的抖动水平分量低于 130 fs (短期固有抖动)。
Infiniium DSO9404A
Infiniium DSOS404A
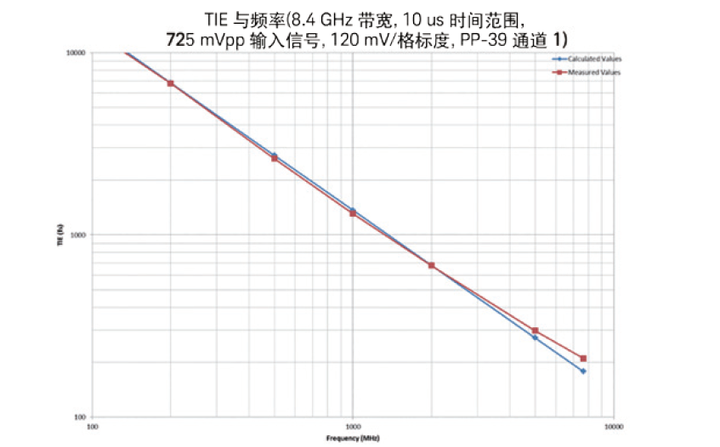
图 13. 示波器厂商通过绘制TIE 测量与输入信号斜率的关系图, 可以提供测量本底抖动的特征(如果使用的是正弦波信号, 则给出TIE 测量值与频率的关系)。除 Infiniium S 系列示波器以外, 所有其他示波器的固有抖动图都与左图类似。从图中可以看出, 在示波器的水平系统成为决定性因素之前, 固有抖动始终是由信号斜率和垂直噪声决定的, 这就叫做测量本底抖动。S 系列的抖动曲线与垂直噪声和斜率存在直接关系, 这表明示波器水平系统对总体固有抖动没有任何影响。Infiniium S 系列在处理8 GHz (最大带宽) 输入正弦波信号时, 它的带内固有抖动低于120 fs。
总结
您是否正在评测一台新的示波器,希望确保它能够在广泛的频率范围内全面而精确地显示被测信号?如果是,您所选的示波器就必须具备信号完整性的所有促成因素: 高分辨率、低固有噪声、平坦的频率响应和适当的ENOB。Infiniium S 系列示波器整合了新的时基模块、前端电路设计以及ADC 技术模块,提供出色的测量功能,可以为您提供同类产品中最佳的本底抖动和最出色的垂直信号属性。S 系列覆盖了500 MHz 至8 GHz 的带宽范围,隶属于Infiniium 示波器家族,该家族的实时示波器带宽最高是63 GHz。示波器 | Keysightwww.keysight.com/main/redirector.jspx?action=ref&cname=COLLECTION&ckey=x2015004&lc=chi&cc=CNInfiniium S 系列示波器www.keysight.com/main/redirector.jspx?action=ref&cname=COLLECTION&ckey=x205213&lc=chi&cc=CNhttps://www.keysight.com/main/redirector.jspx?action=ref&cname=COLLECTION&ckey=x205199&lc=chi&cc=CNwww.keysight.com/main/redirector.jspx?action=ref&cname=COLLECTION&ckey=x205199&lc=chi&cc=CN
示波器术语表
ADC (模数转换器): 通常是指示波器中一个将电压转变为数字幅度值的电子元件。ADC 的总体量化电平或输出电平数等于 2n, 其中n 是指ADC 位数。
分辨率位数: 用于衡量示波器在测量信号时可给出的潜在输出电平数,和ADC 位数、高分辨率模式和/或均值模式有关。
ENOB (有效位数): 通常表示 ADC 或示波器的动态范围。ENOB 考虑到了噪声和其他垂直失真来源。ADC 芯片的ENOB 会比整个示波器系统的ENOB 要高。
滤波器: 滤波器是指一个具有特定频率响应特征的电路或算法。滤波器可以是模拟电路,也可用DSP 硬件实现或通过软件方法实现,但后者速度较慢。
频率响应: 描述示波器在特定带宽范围内的幅度或相位特征。理想的频率响应图应当极为平坦,且具有砖墙式频响。
前端电路: 指示波器 BNC 输入与 ADC 芯片之间的电路,包括模拟滤波器、1 MΩ 和 50 Ω 路径间的开关转换电路和衰减器(为ADC 适当地缩放信号。
抖动: 指信号边沿对理想水平位置的偏移。示波器是测量目标系统抖动性能的理想工具。然而,示波器本身的固有抖动会对抖动测量造成影响。
固有抖动: 示波器的固有抖动包括示波器内部的抖动测量值,也被称为固有源抖动时钟(SJC)。示波器厂商将其精简为”固有抖 动”,用于表示示波器在短时间内的最低固有抖动。
测量本底抖动: 指示波器为抖动测量信号添加的误差,换句话说,它是示波器测量一个无抖动的理想信号所得到的抖动值。本底抖动的构成不仅包括上文提到的采样时钟抖动,而且还包括垂直误差源产生的抖动,例如垂直噪声和混叠信号谐波。
噪声: 指信号边沿对真正信号的垂向偏移。您无法查看低于示波器噪声电平的信号细节。如果噪声电平高于ADC 量化电平,那么ADC 就达不到其标称的理想位数。前端电路是示波器噪声的最大来源。
分辨率: 示波器ADC 的分辨率是指由模数(A/D) 转换器决定的最小量化电平。示波器对多次采集的时间点求平均值可以得到较低的分辨率。或者,示波器采用整合了过采样技术和DSP 滤波器的高分辨率模式,可以实现较高的分辨率。
采样时钟抖动(SCJ): 指抖动的水平分量。
时基: 指示波器中用于确保水平精度和低采样时钟抖动的电路。